Chapter 8 Line-transect analysis
Overview
Line-transect analysis is used to produce estimates of animal density and/or abundance based upon survey data. The main LTabundR function for conducting line-transect analysis is lta(). This is a complex function with many steps, but the function’s three most important jobs are these:
to estimate a detection function for a species or pool of similar species. A “detection function” is a statistical model of how the species’ detectability declines the farther individuals occur from the survey trackline. The model allows the user to estimate the width of their survey strip, which thus allows the user to estimate the total area that was effectively surveyed during the transect. To avoid biases and other statistical pitfalls, detection functions have to be estimated using data from formal transect effort during which observer effort adheres to standard protocols. Typically that means
OnEffortisTRUE,EffTypeis"S"or"N"(and in some cases"F"), andBftis6or lower — but you can specify those conditions yourself when you create your list of settings. Detection function performance hinges upon an adequate sample size of sightings, so it is typical for the dataset used in this stage to span as many years and regions as are available and appropriate.to estimate animal density based on the detection function’s survey strip estimate and the encounter rate for the species during periods of systematic effort, in which transects are placed in a systematic, design-based way throughout the study area. It is essential – at least in the vast majority of cases – that only systematic effort is used here (i.e.,
EffTypeis"S") in order to avoid bias. This means that only a subset of the survey data used to estimate the detection function may be used for estimating abundance, but that is acceptable as long as observer protocols do not differ between the two subsets of the data. Furthermore, density is typically estimated for a single year and region at a time, which means the data used in this stage of the analysis will be reduced even further. Once density is estimated, it is straightforward to then estimate animal abundance within a given area, such as a geostratum.to describe the uncertainty in these estimates, usually in the form of a Coefficient of Variation (CV) and/or 95% confidence intervals (95% CI). To estimate uncertainty, an iterative bootstrapping routine occurs in which segments of survey data are resampled with replacement and the entire estimation processes is repeated a large number of times (typically 1,000 to 10,000 times). This is the major time-consuming aspect of the
lta()process.
To prepare survey data for this kind of analysis, the data need to be processed in a few specific ways: (1) the data need to adhere to a common structure, (2) the data need columns indicating which sections of the survey should be used for estimating the detection function, (3) the sightings need columns confirming that they are also valid to include when estimating the detection function, and (4) the survey needs to be split into segments of similar effort and common length for resampling during bootstrap process for estimating uncertainty.
This is precisely what process_surveys() does based on the settings you feed to it. The process_surveys() function (1) formats the data into an R object of a specific structure (we refer to it as a cruz object); (2) adds a column named use to every row indicating whether or not it should be used in detection function estimation (TRUE means use, FALSE means don’t); (3) adds a column named included to every sighting indicating whether or not it should be used in detection function estimation (TRUE means include, FALSE means don’t); and (4) adds a column named seg_id to every row indicating the numeric ID of the effort segment it falls within.
That brings us to this chapter, in which we feed the cruz object returned by process_surveys() to the lta() function. This function will produce detection functions using the data where use is TRUE and the sightings where included is TRUE, then filter those data further – to systematic effort only (typically, EffType = "S" and Bft is 6 or less) for a single year and/or region – in order to estimate density/abundance. To emphasize that final point: all segments used in abundance estimation are also used for modeling the detection function, but not necessarily vice versa; the data used in abundance estimation will usually be a subset of those used for detection function modeling.
At minimum, the lta() function calls for four primary arguments in addition to your cruz object:
For context, the full set of input options for the lta() function is as follows:
lta(cruz,
Rg0,
fit_filters,
df_settings,
estimates,
use_g0 = TRUE,
abund_eff_types = c("S"),
abund_bft_range = 0:6,
bootstraps = 0,
seed = NULL,
results_file = NULL,
toplot = TRUE,
verbose = TRUE
)Below we explain each of the key required inputs, discuss other optional inputs, and explore the results produced by lta().
Key inputs
cruz
This is the cruz object you have generated with process_surveys(). Before running lta(), ensure that this cruz object is filtered only to the years, regions, and sighting conditions you would like to use for detection function fitting. Filter your cruz object with full flexibility using LTabundR::filter_cruz(). Note that filtering for detection function fitting is typically less stringent than filtering for downstream steps for abundance estimation, since as many sightings are included as possible to combat low sample sizes, as long as sightings were observed using standard methods in an unbiased search pattern, and as long as you do not expect detectability to vary across years and regions.
Here we will work with a version of the 1986-2020 Central North Pacific survey data we processed a few pages back.
As it is provided, this dataset does not need any filtering for our purposes here.
We will use these data to estimate the abundance of striped dolphins (Stenella coeruleoalba), Fraser’s dolphins (Lagenodelphis hosei), and melon-headed whales (Preponocephala electra) within the WHICEAS study area in 2017 and 2020. We will group these three species into a ‘species pool’ in order to gain a sufficient sample size for fitting a detection function. We will then use “Species” as a covariate within the detection function model, along with other variables including Beaufort Sea State, ship name, and log-transformed group size.
Rg0
This input is the result of LTabundR::g0_model(), which is a data.frame with relative trackline detection probabilities, Rg(0), for each species in each Beaufort sea state. See LTabundR dataset data("g0_results"), used below, as an example, or see the vignette chapter here.
This is an optional input. If not provided, g(0) will be assumed to 1.0, and its CV will be assumed to be 0. Alternatively, you can manually specify values for g(0) and its CV in the estimates argument below.
Here we will use a data.frame of Rg(0) estimates based on the same survey years, 1986 - 2020, which has been provided as a built-in dataset:
This dataset looks as follows. Each row is a Rg(0) estimate for a species group in a given Beaufort state, with details on the data used to generate that estimate and the CV of the estimate. For the lta() routine, the critical columns are spp, bft, Rg0, and Rg0_CV.
Rg0 %>% head
title spp bft Rg0 ESW n Rg0_SE Rg0_CV
1 Delphinus spp 005-016-017 0 1.0000000 4.080839 10 0.00000000 0.0000000
2 Delphinus spp 005-016-017 1 0.8906733 3.825992 10 0.14676242 0.1647769
3 Delphinus spp 005-016-017 2 0.7673453 3.539379 10 0.20598906 0.2684438
4 Delphinus spp 005-016-017 3 0.6110636 3.233778 10 0.15815676 0.2588221
5 Delphinus spp 005-016-017 4 0.4716416 2.923286 10 0.09953197 0.2110330
6 Delphinus spp 005-016-017 5 0.3903391 2.622181 10 0.10054686 0.2575885
ESW_SE sits sits_p segs segs_p
1 0.12357710 38 0.01747126 223 0.004604489
2 0.10611887 188 0.08643678 1570 0.032417253
3 0.08559829 483 0.22206897 4856 0.100266358
4 0.06857781 574 0.26390805 9358 0.193223349
5 0.06809921 606 0.27862069 18411 0.380149078
6 0.08406913 270 0.12413793 12668 0.261568004fit_filters
The fit_filters input specifies how to filter the data before fitting the detection function. The filtering here is focused on species and truncation distances, not the regions or years included in the data. To filter by region, year or cruise number, use the function filter_cruz() before beginning the lta() process.
The fit_filters input accepts a named list, which in our example will look like this:
fit_filters = list(spp = c('013', '026', '031'),
pool = 'Multi-species pool 1',
cohort = 'all',
truncation_distance = 5,
other_species = 'remove')spp: A character vector of species codes. Using multiple species codes may be useful when you have low sample sizes for a cohort of similar species.cohort: The cohort containing these species, provided as a name or a number indicating which slot incruz$cohortsshould be referenced.truncation_distance: The truncation distance to apply during model fitting.
The remaining inputs are optional (i.e., they all have defaults):
pool: A character string, providing a title for this species pool. If not specified, the species codes used will be concatenated to produce a title automatically.other_species: A character vector with four recognized values:- If
"apply"(the default if not specified), the species code will be changed to"Other"for sightings in which the species was in a mixed-species group but was not the species with the largest percentage of the total school size. In those cases, the focal species was not as relevant to the detection of the group as the “other” species was, which may bias the detection function. This option creates a factor level for the detection function to use (when"species"is a covariate) to distinguish between cue-relevant species that are within the specified pool and those that are not. - The second option for
other_speciesis"ignore", which does not reassign species codes to"Other", and ignores whether the species of interest held the plurality for a mixed-species group. - The third option is
"remove": any species re-assigned to"Other"will be removed before the detection function is fit; this can be useful if only a small number of species are re-assigned to"Other", which would then obviatespeciesas a viable covariate (since the sample size of allspecieslevels would be unlikely to exceeddf_settings$covariates_n_per_level– see below). - The fourth and final option is
coerce, which forces all species codes to"Other"for the purposes of detection function fitting and abundance estimation. This is effectively the same as removing ‘species’ from the list of covariates, but this option can be a convenience if you want to quickly toggle the use ofspeciesas a covariate for a specific species pool and/or produce abundance estimates for unidentified taxa (e.g., an ‘Unidentified dolphins’ species pool that includes multiple species codes).
- If
df_settings
The df_settings input specifies how to fit a detection function to the filtered data. It accepts a named list, which in our example will look like this:
df_settings = list(covariates = c('bft','lnsstot','cruise','year','ship','species'),
covariates_factor = c(FALSE, FALSE, TRUE, TRUE, TRUE, TRUE),
covariates_levels = 2,
covariates_n_per_level = 10,
simplify_cue = TRUE,
simplify_bino = TRUE,
detection_function_base = 'hn',
base_model = '~1',
delta_aic = 2)(Note that all of these inputs have defaults, and are therefore optional.)
covariatesCovariates you wish to include as candidates in detection function models, provided as a character vector. The covariates must match columns existing withincruz$cohorts$<cohort_name>$sightings. (For help adding custom covariates to this dataset, see here). Note that the function will ignore case, coercing all covariates to lowercase. Default: no covariates.covariates_factorA Boolean vector, which must be the same length ascovariates, indicating whether each covariate should be treated as a factor instead of a numeric. Default:NULL.covariates_levelsThe minimum number of levels a factor covariate must have in order to be included as an eligible covariate. Default:2.covariates_n_per_levelThe minimum number of observations within each level of a factor covariate. If this condition is not met, the covariate is excluded from the candidates. Default:10.simplify_cueA Boolean, with defaultTRUE, indicating whether or not cue codes should be simplified before being included as a covariate in detection function fitting. This can help to overcome the factor sample size limitations that may prevent inclusion as a covariate. IfTRUE, cues0,1,2,4, and7are coerced to5, representing ‘other’ cues.simplify_binoA Boolean, with defaultTRUE, indicating whether or not sighting method codes should be simplified before being included as a covariate in detection function fitting. This can help to overcome the factor sample size limitations that may prevent inclusion as a covariate. IfTRUE, methods other than4are all coerced to5, representing ‘other’ methods.detection_function_baseThe base key for the detection function, provided as a character vector. Accepted values are"hn"(half-normal key, the default, which exhibits greater stability when fitting to cetacean survey data; Gerrodette and Forcada 2005),"hr"(hazard-rate), orc("hn", "hr), which will loop through both keys and attempt model fitting.base_modelThe initial model formula, upon which to build using candidate covariates. If not provided by the user, the default is"~ 1".delta_aicThe AIC difference between the model yielding the lowest AIC and other candidate models, used to define the best-fitting models. Typically, AIC differences of less than 2 (the default) indicate effectively equal model performance. If this value is not zero, then model averaging will be done: if multiple models are withindelta_aicof the model with the lowest AIC, all “best” models will be used in subsequent steps and their results will be averaged. SeeDetailsbelow.
estimates
The estimates input specifies which estimates of density and abundance to produce based on the fitted detection function. This input accepts a list of sub-lists, which in our example will look something like this:
This example shows only a single sub-list, specifying how to generate a density/abundance estimate for striped dolphins (species code 013) within the “WHICEAS” geostratum for 2017.
spp: A character vector of species codes.title: A title for this abundance estimate, given as a character vector, ’ e.g.,"Striped dolphin - pelagic". If left blank, the species code(s) will be concatenated to use as a title.years: A numeric vector of years, used to filter data to include only effort/sightings from these years.regions: A character vector of geostratum names, used to filter the data. Any segment or sighting occurring within any (but not necessarily all) of the providedregionswill be returned. This holds true for nested regions: for example, in analyses from the Central North Pacific, in which the Hawaii EEZ geostratum ("HI-EEZ") is nested within the larger geostratum representing the entire CNP study area ("OtherCNP"), an input ofregions = "OtherCNP"will return segments/sightings both inside the Hawaii EEZ and outside of it.
You also have the option of manually specifying other filters & arguments. Each of these sub-lists accepts the following named slots:
cruises: An optional numeric vector of cruise numbers, used to filter data to include effort/sighting from only certain cruises. Ignored ifNULL.regions_remove: A character vector of geostratum names, similar to above. Any segment or sighting occurring within any of theseregions_removewill not be returned. Using the example above, ifregions = "OtherCNP"andregions_remove = "HI-EEZ", only segments occuring withinOtherCNPand outside ofHI-EEZwill be returned. This can be particularly useful for abundance estimates for pelagic stock that exclude nested insular stocks.g0: If left as the defaultNULL, thelta()function will automatically estimate the weighted trackline detection probability (g0) according to the distribution of Beaufort sea states contained within the survey years/regions for which density/abundance is being estimated (this is done using theLTabundRfunctiong0_weighted()). This will only be done if theRg0input above is notNULL; if it is and you do not provide g(0) values here,g0will be coerced to equal 1. To coerceg(0)to a certain value of your own choosing, you can provide a numeric vector of length 1 or 2. If length 1, this value represents g(0) for all groups regardless of size. If length 2, these values represent g(0) for small and large group sizes, as defined byg0_thresholdbelow.g0_cv: Similar to g0 above: if leftNULL, the CV of theg(0)estimate will be automatically estimated based on weighted survey conditions. Alternatively, you can manually specify a CV here, using a numeric vector of length 1 or 2. If you do not specify a value andRg0input is NULL,g0_cvwill be coerced to equal 0.g0_threshold: The group size threshold between small and large groups.alt_g0_spp: An alternate species code to use to draw Rg(0) values from theRg0input. This is useful in the event that Rg(0) was not estimated for the species whose density/abundance you are estimating, but there is a similarly detectable species whose Rg(0) parameters have been estimated.combine_g0: A Boolean, with defaultFALSE. IfTRUE, weighted g0 estimates will be produced separately for each species code provided (specifically, for each unique row in theRg0table that is found after filtering by the species codes you provide in this estimate), THEN average those estimates together. This can be useful when you do not have a Rg(0) estimates for a certain species, but you can approximate g(0) by averaging together estimates from multiple species (e.g., averaging together weighted g(0) from across rorqual species in order to get a weighted g(0) estimate for ‘Unidentified rorquals’).region_title: An optional character vector indicating the title you would like to give to the region pertaining to this estimate. This can be useful if you have a complicated assemblage of regions you are combining and/or removing. If not supplied, the function will automatically generate aregion_titlebased onregionsandregions_remove.forced_effort: If this is a single numeric value instead ofNULL(NULLis the default), this value will be used as the survey effort, in km, in a brute-force method; this same value will be used for every year and region. This is only helpful if you are looking for a relatively easy way to compare results from your own analysis to another (e.g., comparingLTabundRresults to NOAA Fisheries reports of cetacean abundance in the central and eastern Pacific through 2022, in which effort was calculated slightly differently).area: If this is a single numeric value instead ofNULL(NULLis the default), this value will be used as the area of the region in which abundance is being estimated, in square km, in a brute-force approach. If leftNULL, the function will calculate the final area of the survey area resulting from theregionsandregions_removefilters above.remove_land: A Boolean, with defaultTRUE, indicating whether or not land area should be removed from the survey area before calculating its area for abundance estimation. This term is only referenced if area is not specified manually.
Here is the full estimates list for all the species-year-geostratum combinations for which we want to estimate density/abundance:
estimates <- list(
list(spp = '013',
title = 'Striped dolphin',
years = 2017,
regions = 'WHICEAS'),
list(spp = '013',
title = 'Striped dolphin',
years = 2020,
regions = 'WHICEAS'),
list(spp = '026',
title = 'Frasers dolphin',
years = 2017,
regions = 'WHICEAS'),
list(spp = '026',
title = 'Frasers dolphin',
years = 2020,
regions = 'WHICEAS'),
list(spp = '031',
title = 'Melon-headed whale',
years = 2017,
regions = 'WHICEAS'),
list(spp = '031',
title = 'Melon-headed whale',
years = 2020,
regions = 'WHICEAS'))Each of these sub-lists specifies the details for a single estimate of density/abundance, making it possible to produce multiple estimates from the same detection function model. Generally, there needs to be a sub-list for each species-region-year combination of interest.
You can imagine that building up these sub-lists can get tedious. It can also introduce the possibility of error or inconsistencies across estimates of multiple species. To address that issue, LTabundR includes the function lta_estimates(), which makes your code for preparing an estimates object much more efficient. That function is demonstrated in the Case Studies chapters.
To run lta() with the above inputs, use this code:
After running lta(), quickly review results:
results$estimate
title species Region Area year segments km
1 Striped dolphin 013 (WHICEAS) 402948.7 2017 29 2981.643
2 Striped dolphin 013 (WHICEAS) 402948.7 2020 32 4439.758
3 Frasers dolphin 026 (WHICEAS) 402948.7 2017 29 2981.643
4 Frasers dolphin 026 (WHICEAS) 402948.7 2020 32 4439.758
5 Melon-headed whale 031 (WHICEAS) 402948.7 2017 29 2981.643
6 Melon-headed whale 031 (WHICEAS) 402948.7 2020 32 4439.758
Area_covered ESW_mean n g0_est ER_clusters D_clusters N_clusters
1 11152.53 3.740395 3 0.3374269 0.0010061565 0.0004020127 161.99051
2 17214.00 3.877238 3 0.3047672 0.0006757124 0.0002873431 115.78454
3 NA NA 0 0.3582468 0.0000000000 0.0000000000 0.00000
4 18180.18 4.094859 1 0.3280294 0.0002252375 0.0000838415 33.78383
5 10064.83 3.375597 2 0.3778425 0.0006707710 0.0002643002 106.49942
6 15641.91 3.523144 2 0.3472579 0.0004504750 0.0001846167 74.39106
size_mean size_sd ER D N g0_small g0_large
1 31.95079 0.5780968 0.03214749 0.01286257 5182.957 0.3374269 0.3374269
2 53.95865 2.7402089 0.03646053 0.01549657 6244.322 0.3047672 0.3047672
3 NA NA 0.00000000 0.00000000 0.000 0.3582468 0.3582468
4 261.32841 NA 0.05886095 0.02191017 8828.673 0.3280294 0.3280294
5 185.98103 96.4369707 0.12475069 0.04786945 19288.934 0.3778425 0.3778425
6 324.68110 58.0826568 0.14626070 0.05954113 23992.025 0.3472579 0.3472579
g0_cv_small g0_cv_large
1 0.110 0.110
2 0.115 0.115
3 1.204 1.204
4 1.294 1.294
5 1.321 1.321
6 1.214 1.214More details on the lta() output are provided below.
Variance estimation
By default, the lta() function produces a single estimate of the detection function and a single estimate of density/abundance estimate for each sub-list within estimates(). However, you can obtain the coefficient of variation (CV) of those estimates by activating the function’s bootstrap variance estimation feature. To do this, add bootstraps as an input specifying a large number of iterations (1,000 iterations is standard, but we suggest first testing your code with 5 - 10 bootstraps before committing; the function typically requires ~1 hour per 100 bootstraps.).
For the purposes of example, we will use just 100 bootstrap iterations:
This command will first produce official estimates of the detection function and density/abundance, then it will repeat the analysis for the number of iterations you have specified. In each iteration, survey segments are re-sampled according to standard bootstrap variance estimation methods (see more details below, in “Behind the Scenes”). The seed input is optional and can make the bootstrap process reproducible if you provide an integer. If you do not require reproducibility, leave this input out or simply set it to NULL.
We describe the output of lta() in detail below, but here is a brief snapshot of the bootstrap results, for one of the species-region-year estimates:
results$bootstrap$summary[2, ] %>% as.data.frame
title Region year species iterations ESW_mean g0_mean g0_cv
1 Frasers dolphin (WHICEAS) 2020 026 100 3.956959 0.3511438 1.259039
km ER D size Nmean Nmedian Nsd
1 4596.024 0.05367551 1347294 261.3284 542890335952 3135.002 2647920809896
CV L95 U95
1 4.877451 15967362822 18458271422370The Delta Method
LTabundR provides a function, lta_delta_method(), that allows you to re-calculate the CV and 95% Confidence Intervals of your density/abundance estimate using a modification of the Delta Method. The reason we provide this is that abundance estimates using our bootstrap approach have been found found to be extremely sensitive to the distribution of g(0) when it is included in the bootstrap procedure. Given that the true distribution of errors in g(0) is not known, an alternative approach is to add the uncertainty attributed to g(0) estimates after the bootstrap process using the delta method, which assums that the resulting abundance estimates are log-normally distributed. This is what we implement in lta_delta_method(): that function takes the output of lta() call in which bootstrap iterations were performed, then replaces the CV and L95 and U95 confidence intervals within the output using the delta method.
# Put your lta() output into a list
ltas <- list(results)
# Run delta method
results_dm <- lta_delta_method(ltas,
verbose=FALSE)Now view how results have changed from above:
results_dm[[1]]$bootstrap$summary[2, ] %>% as.data.frame
title Region year species iterations ESW_mean g0_mean g0_cv
1 Frasers dolphin (WHICEAS) 2020 026 100 3.956959 0.3511438 1.259039
km ER D size Nmean Nmedian Nsd
1 4596.024 0.05367551 1347294 261.3284 542890335952 3135.002 2647920809896
CV L95 U95 D_real N_real CV_delta L95_delta U95_delta
1 1.814077 1330.338 58590.73 0.02191017 8828.673 1.814077 1330.338 58590.73
CV_boot L95_boot U95_boot
1 4.877451 15967362822 18458271422370Other inputs
As mentioned near the top, there are several optional input arguments that lend further control over the lta() procedure.
lta(cruz,
Rg0,
fit_filters,
df_settings,
estimates,
use_g0 = TRUE,
abund_eff_types = c("S"),
abund_bft_range = 0:6,
bootstraps = 10,
seed = 123,
toplot = TRUE,
verbose = TRUE)use_g0: A Boolean, with defaultTRUE, indicating whether or not to use customg(0)value(s). IfFALSE, the assumedg(0)value will be 1. This is an easy way to toggle on-and-off automated g(0) estimation and/or ignore manually supplied g(0) values.abund_eff_types: TheEffTypevalues that are acceptable as systematic effort when estimating density/abundance. The default is just"S"(systematic effort), but in some surveys/cases you may wish to use fine-scale effort ("F") too.abund_bft_range: The Beaufort sea state values that are acceptable during systematic effort for estimating density/abundance. The default is sea states 0 - 6.toplot: A Boolean, with defaultTRUE, indicating whether detection function plots (Distance::plot.ds()) should be displayed as the candidate models are tested.seed: As stated above, this input can make the bootstrap process reproducible if you provide an integer. If you do not require reproducibility, leave this input out or simply set it toNULL.verbose: A Boolean, with defaultTRUE, indicating whether or not updates should be printed to the Console.
Data checks & QA/QC
To assist analysts with checking their data for any missing data that may impact the sample sizes for detection function fitting and/or abundance estimation, LTabundR provides the function lta_checks().
This function is designed for a QA/QC step before running the lta() function. It checks for missing data in covariate columns (e.g., "Bft" or "year"), group size columns (if "lnsstot" is a desired covariate), and the perpendicular distance column ("PerpDistKm"). The function runs these checks twice: first for all sightings to be used in fitting the detection function (where missing data are not preferred but would not be fatal; sightings with incomplete data would simply be removed, lowering your sample size for the model fit), and second for detections that contribute to each point estimate of density/abundance (here missing data is disastrous; unless the missing data are filled in, the detection would be removed and the density estimate would be affected.) This function can be used to pinpoint and address holes in the data as the user sees fit.
The function uses the exact same objects that are passed as inputs to the lta() function. It returns messages to your Console flagging any missing data, as well as a list() object with all details necessary for locating rows with missing data in your cruz object.
Note that the final lines of those messages provided instructions for what to do in the event that you find missing data that you wish to address (e.g., perhaps you want to replace a missing group size with the average group size from the survey-region-year).
Output
During processing
While lta() is running, it will print things to the Console (if verbose is TRUE), plot diagnostic plots of how the study area is being calculated (if toplot is TRUE), and plot detection function model candidates (if toplot is TRUE). To demonstrate this, we will run the estimate for striped dolphins in 2017 only, without variance bootstrapping. To expedite processing, we will manually supply g(0) values from Bradford et al. (2022) (this saves about 3 minutes per estimate):
new_estimates <- list(
list(spp = '013',
title = 'Striped dolphin',
years = 2017,
regions = 'WHICEAS',
g0 = 0.35,
g0_cv = 0.19))
# Run it:
demo <- lta(cruz, Rg0, fit_filters, df_settings, new_estimates, bootstraps = 0)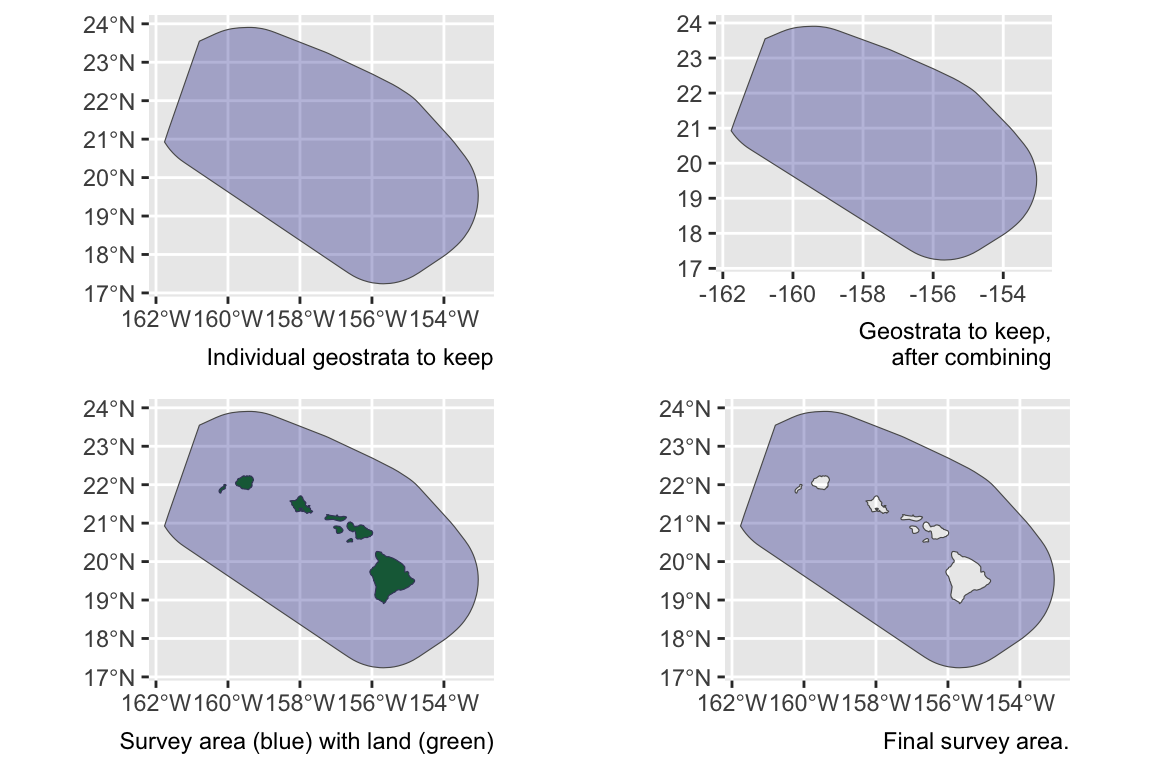
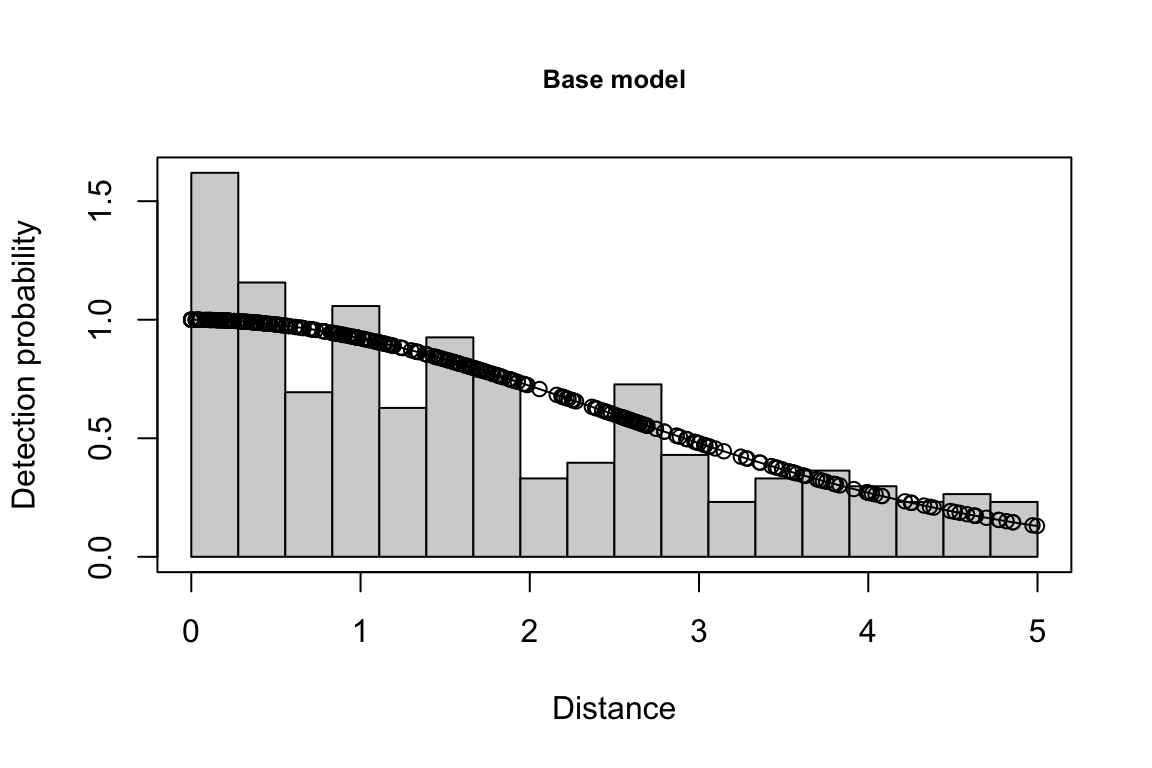
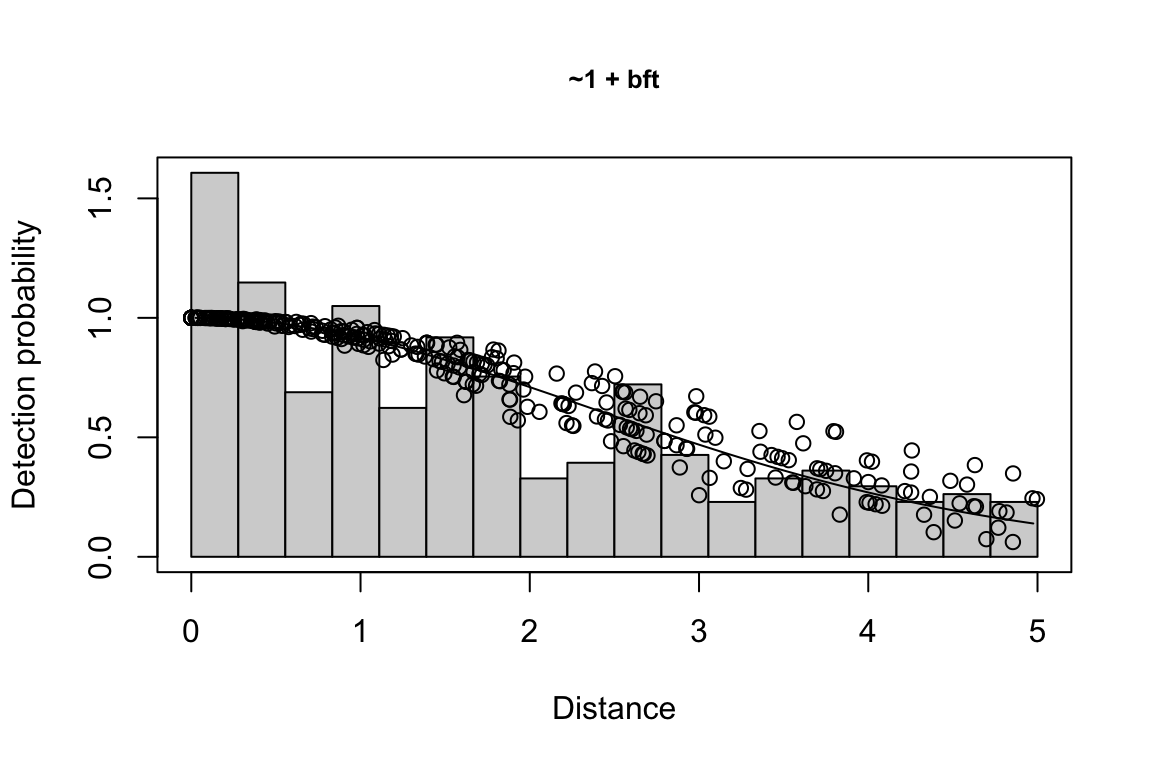
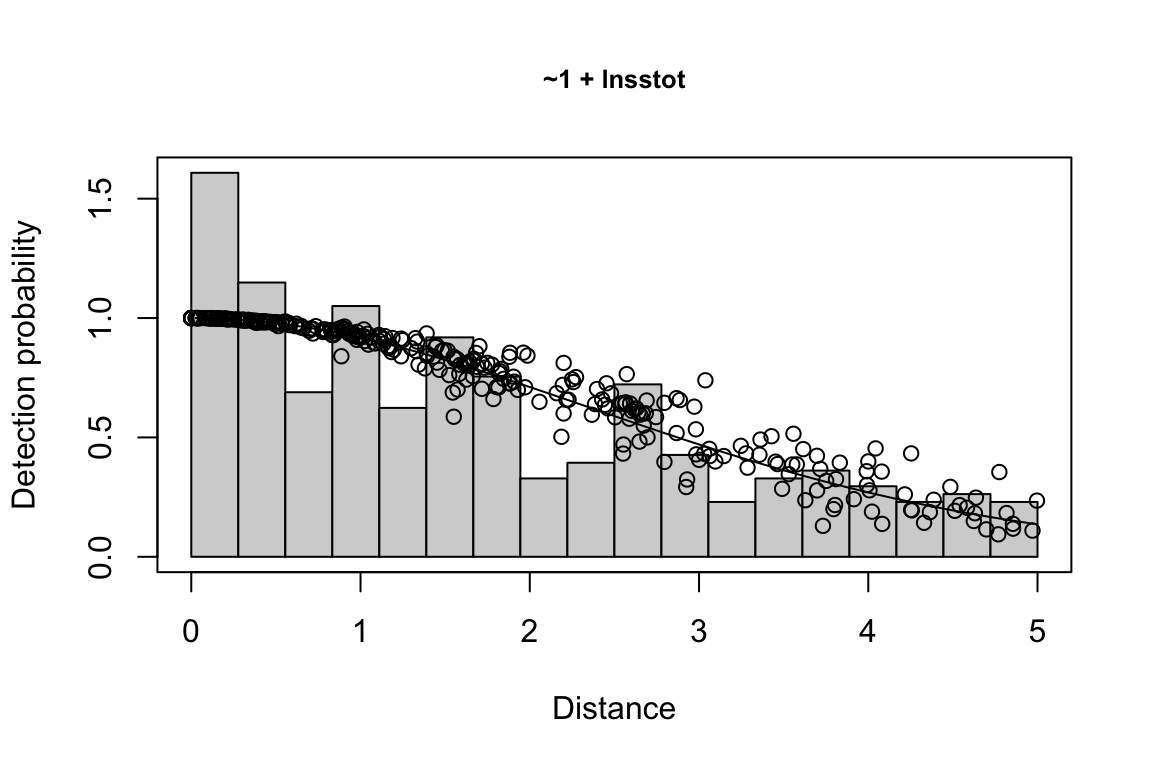
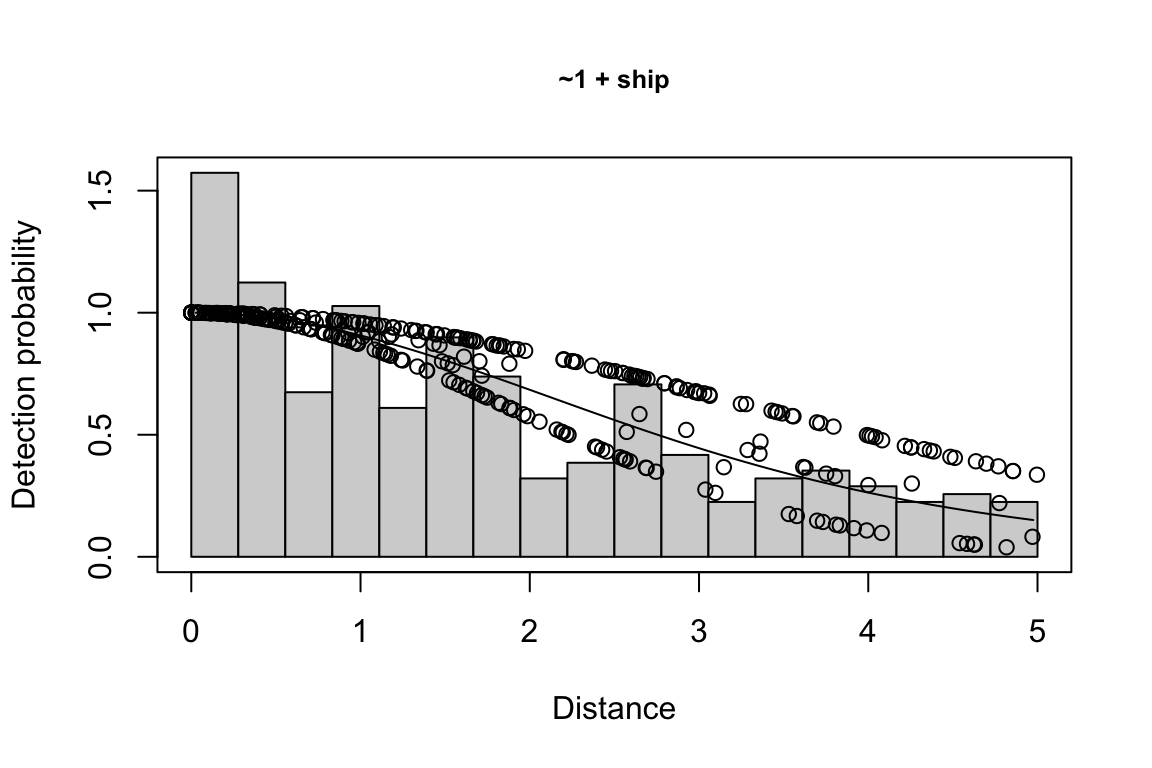
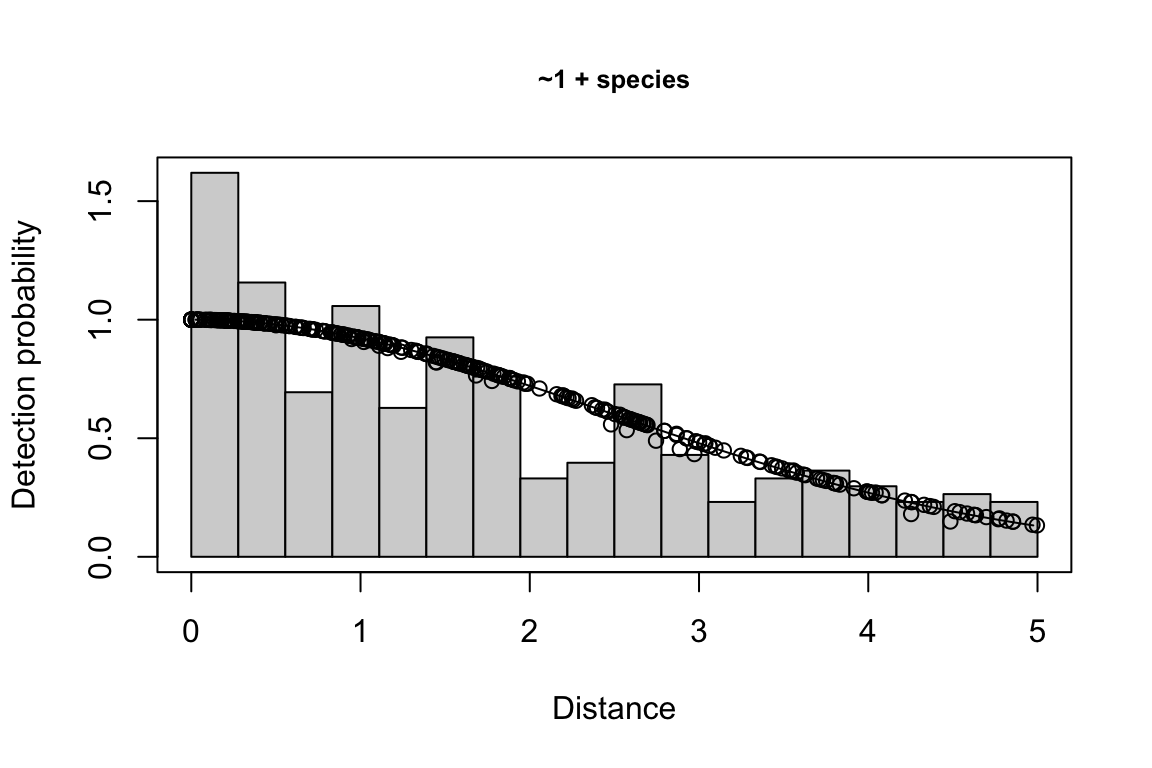
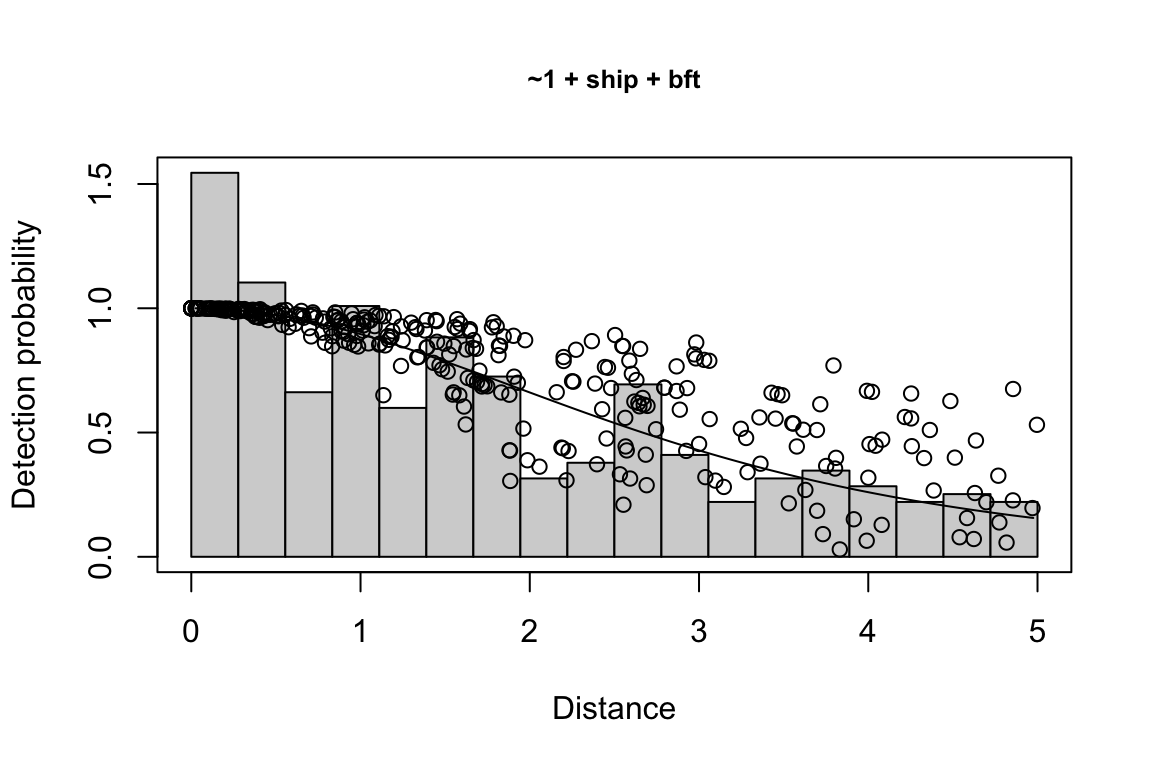
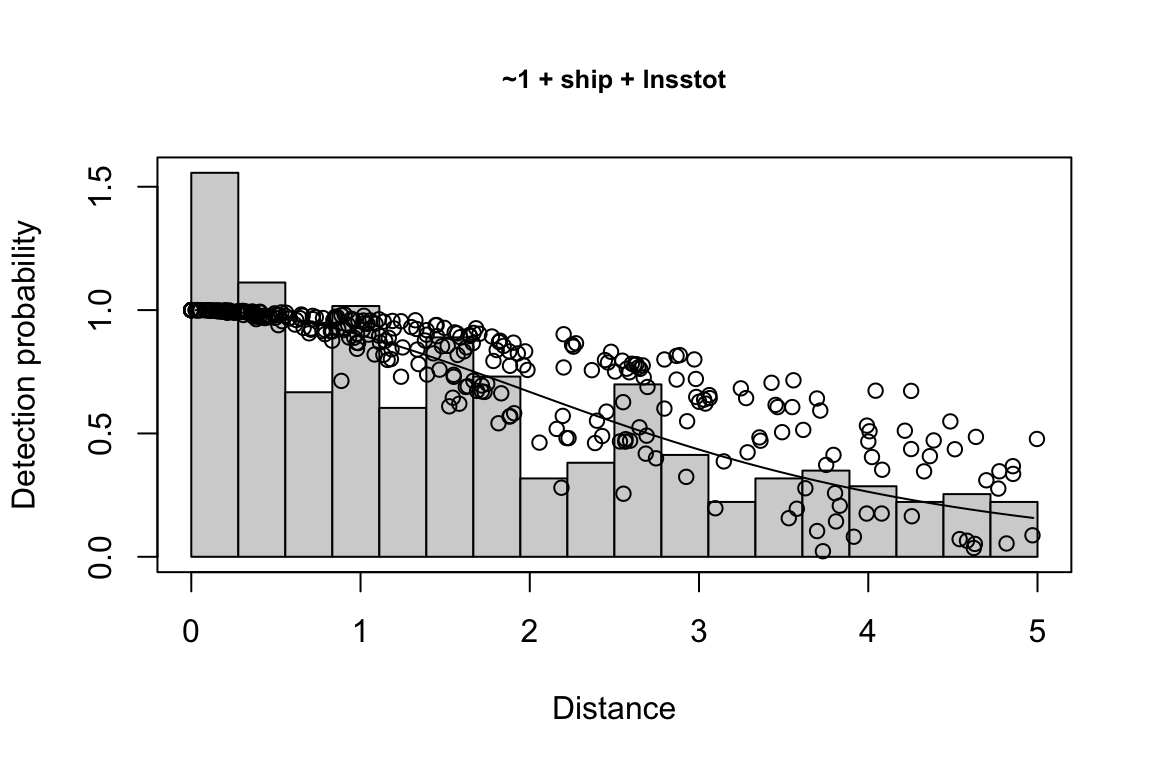
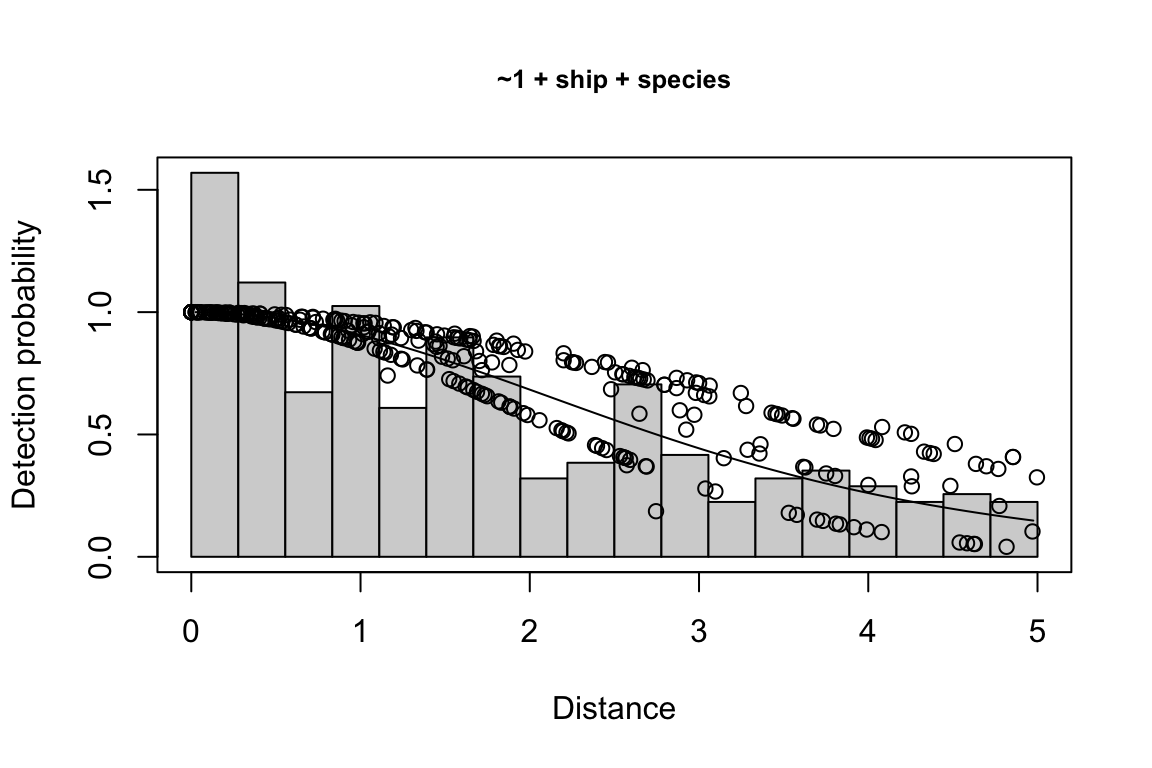
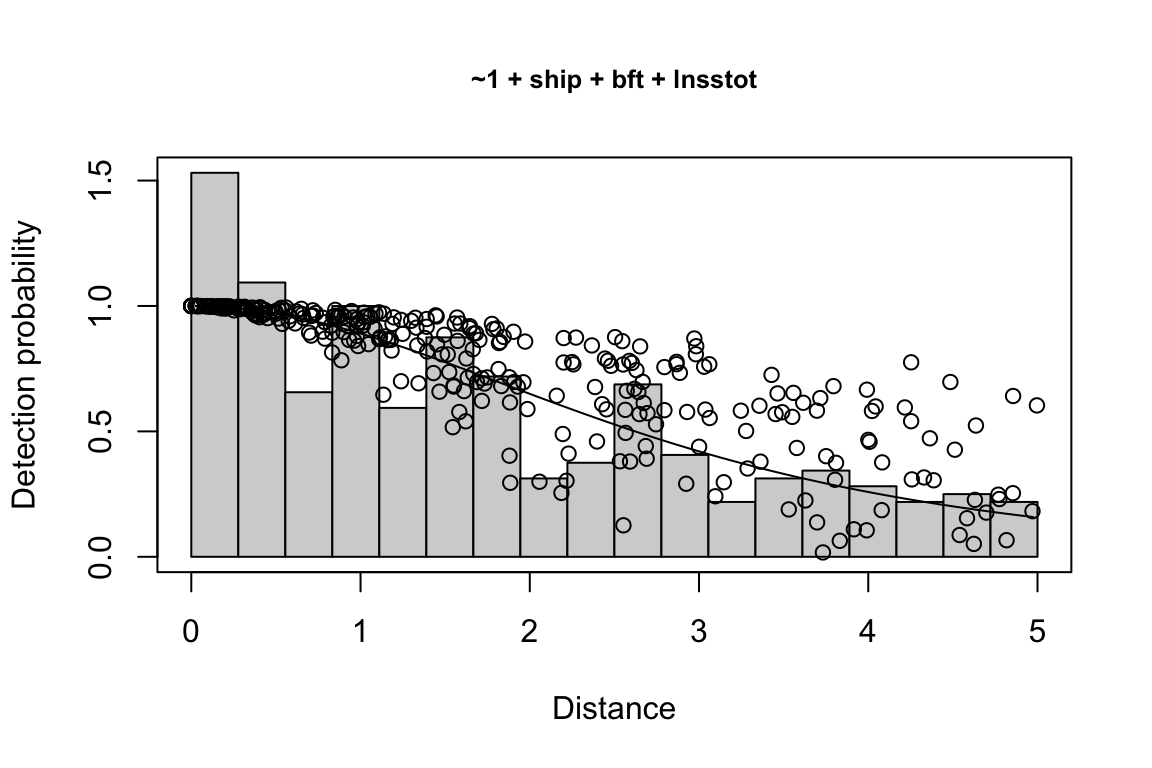
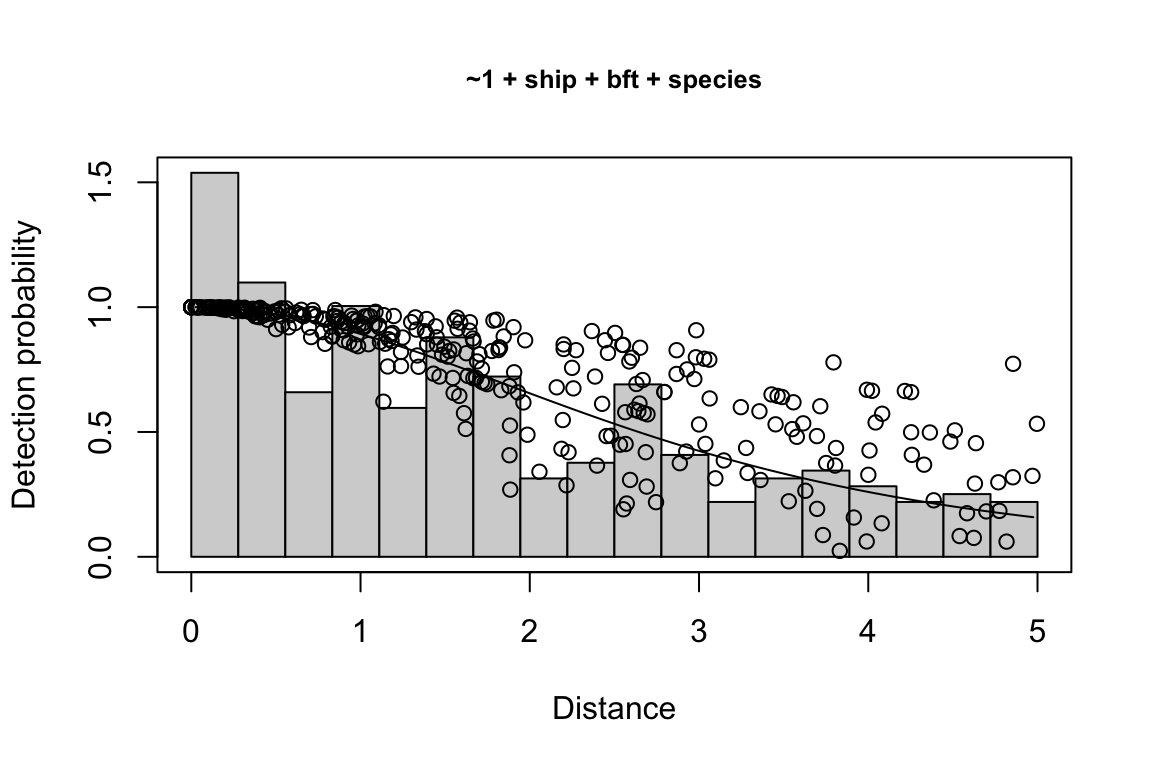
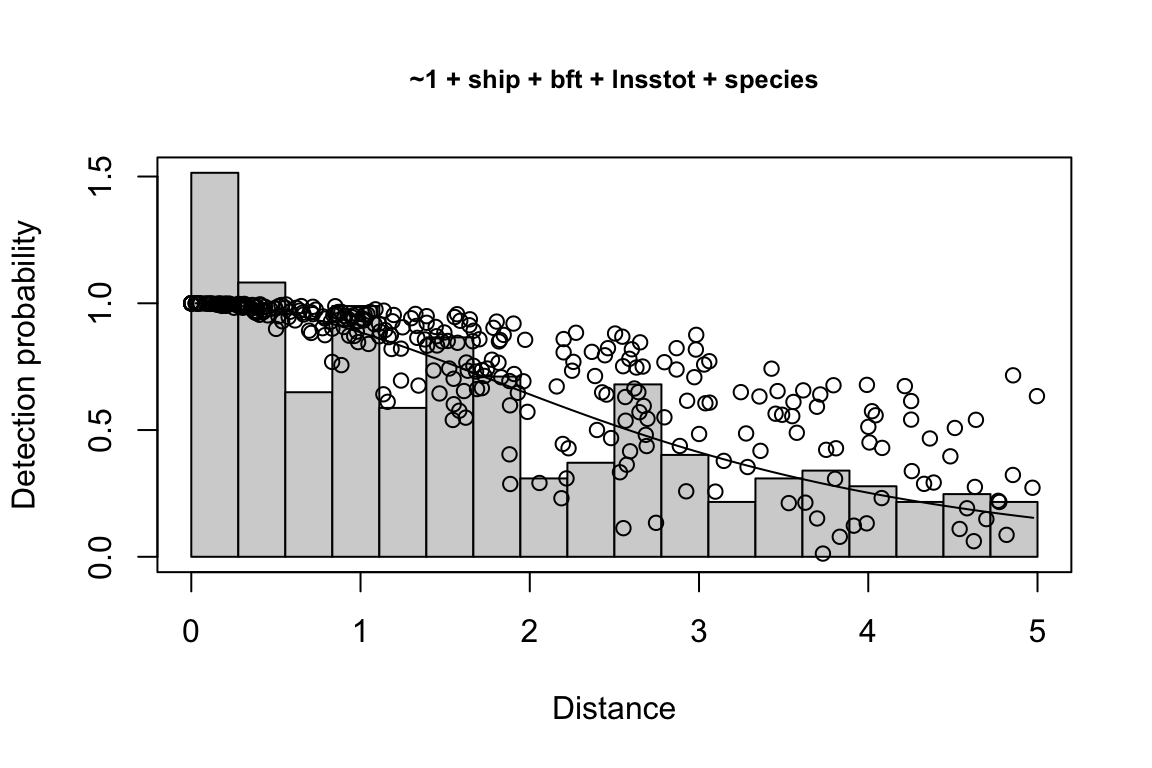
Additionally, windows will appear showing details for the detection function models and details of the density/abundance estimate.
Outputs
The lta() function returns a list of objects. To demonstrate this output, we will pull back in the dataset representing the result of the analysis above, for all three species in both years (with 10 bootstrap iterations):
This list of results has five slots:
pool: The species pool pertaining to these estimates.inputs: A list of the inputs used to produce these estimates.estimate: A table of density/abundance estimates for each species/region/year combination specified in theestimatesinput.
results$estimate
title species Region Area year segments km
1 Striped dolphin 013 (WHICEAS) 402948.7 2017 29 2981.643
2 Striped dolphin 013 (WHICEAS) 402948.7 2020 32 4439.758
3 Frasers dolphin 026 (WHICEAS) 402948.7 2017 29 2981.643
4 Frasers dolphin 026 (WHICEAS) 402948.7 2020 32 4439.758
5 Melon-headed whale 031 (WHICEAS) 402948.7 2017 29 2981.643
6 Melon-headed whale 031 (WHICEAS) 402948.7 2020 32 4439.758
Area_covered ESW_mean n g0_est ER_clusters D_clusters N_clusters
1 11152.53 3.740395 3 0.3374269 0.0010061565 0.0004020127 161.99051
2 17214.00 3.877238 3 0.3047672 0.0006757124 0.0002873431 115.78454
3 NA NA 0 0.3582468 0.0000000000 0.0000000000 0.00000
4 18180.18 4.094859 1 0.3280294 0.0002252375 0.0000838415 33.78383
5 10064.83 3.375597 2 0.3778425 0.0006707710 0.0002643002 106.49942
6 15641.91 3.523144 2 0.3472579 0.0004504750 0.0001846167 74.39106
size_mean size_sd ER D N g0_small g0_large
1 31.95079 0.5780968 0.03214749 0.01286257 5182.957 0.3374269 0.3374269
2 53.95865 2.7402089 0.03646053 0.01549657 6244.322 0.3047672 0.3047672
3 NA NA 0.00000000 0.00000000 0.000 0.3582468 0.3582468
4 261.32841 NA 0.05886095 0.02191017 8828.673 0.3280294 0.3280294
5 185.98103 96.4369707 0.12475069 0.04786945 19288.934 0.3778425 0.3778425
6 324.68110 58.0826568 0.14626070 0.05954113 23992.025 0.3472579 0.3472579
g0_cv_small g0_cv_large
1 0.110 0.110
2 0.115 0.115
3 1.228 1.228
4 1.323 1.323
5 1.326 1.326
6 1.212 1.212df: A named list with details for the detection function.
results$df %>% names
[1] "best_models" "all_models" "best_objects" "sightings" "sample_size"
[6] "curve"
results$df$best_models
Model Key_function Formula Pmean AIC
1 9 hn ~1 + ship + bft + lnsstot 0.5606381 939.636
2 11 hn ~1 + ship + bft + lnsstot + species 0.5547024 940.141
$\\Delta$AIC Covariates tested pool
1 0.000 bft, lnsstot, ship, species Multi-species pool 1
2 0.505 bft, lnsstot, ship, species Multi-species pool 1bootstrap: If bootstrap variance estimation was carried out, the output would also includebootstrap, a named list with results from the bootstrap process, only returned if the bootstraps input is greater than 1.
results$bootstrap$summary %>% head
# A tibble: 6 × 18
# Groups: title, Region [3]
title Region year species iterations ESW_mean g0_mean g0_cv km ER
<chr> <chr> <chr> <chr> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Frasers d… (WHIC… 2017 026 100 NaN 0.383 1.17 2887. 0
2 Frasers d… (WHIC… 2020 026 100 3.96 0.351 1.26 4596. 0.0537
3 Melon-hea… (WHIC… 2017 031 48 3.03 0.854 0.418 2806. 0.0922
4 Melon-hea… (WHIC… 2020 031 100 3.32 0.371 1.16 4596. 0.148
5 Striped d… (WHIC… 2017 013 100 3.79 0.340 0.120 2887. 0.0338
6 Striped d… (WHIC… 2020 013 100 3.89 0.307 0.126 4596. 0.0375
# ℹ 8 more variables: D <dbl>, size <dbl>, Nmean <dbl>, Nmedian <dbl>,
# Nsd <dbl>, CV <dbl>, L95 <dbl>, U95 <dbl>Unusual estimate scenarios
Most line-transect estimates in most areas are relatively straightforward: you want an estimate for a single species in a single year, and your geostrata do not overlap, nor do they need to be stratified or combined in atypical ways.
But there will also be unusual and slightly more complicated scenarios. We outline some of those below and demonstrate how they can be handled within the LTabundR framework.
Species combinations & g(0)
Mixed-species groups
Mixed-species groups can confound detection function model fitting, since your species of interest may not be the predominant species in the group, which means that the other species present may be having a greater influence over the detection function. You can decide how to account for this using the other_species slot in your fit_filters list. See the details on this discussed above.
Species pools
When you don’t have enough sightings of individual species to model a detection function effectively, it can be useful to pool sightings from multiple species who have similar detection characteristics. This is a common tactic by NOAA Fisheries analysts who conduct cetacean surveys in the Central North Pacific.
When you do this, you typically need to make the following changes to a “normal” lta() call:
In your
df_settingslist, consider addingspeciesas a covariate, and ensure that you specify that it should be treated as a factor. This may improve detection function model fit.In your
fit_filterslist, specify multiple species codes and name your species pool accordingly (e.g., “Multi-species pool 1”).In your
fit_filterslist, specify how to handle “Other” species (see above).In your
estimateslist, add a sub-list for each species-region-year for which you want a density/abundance estimate.
We took all of these steps in the example above with striped dolphins, Fraser’s dolphins, and melon-headed whales. Use that code as a guide.
Pooling similar species
Species that can be confused with one another may need to be pooled together for abundance estimation. For example, in the northeast Pacific, sei whales, Bryde’s whales, and fin whales can co-occur but they are difficult to distinguish in the field. They are also relatively uncommon, and may need to be pooled with other species in order to obtain a sound detection function model. There is also a species code, "199", to indicate sightings that could be any of these species. That species code could be used to estimate the “abundance” of this ambiguous species code, but it does not have a sample size sufficient for estimating Relative g(0).
To handle this special case, we will follow all the steps taken for a multi-species pool, as discussed above. Additionally, in our estimates sub-list(s), we will specify (1) that the ambiguous species code should be used for the abundance estimate, and (2) that the g(0) should represent the average of the weighted g(0) estimates for each of the candidate species:
estimates <- list(
list(spp = '199',
title = "Sei/Bryde's/Fin whale",
alt_g0_spp = c('072', '073', '099', '074'),
combine_g0 = TRUE))You can also multiple species within the spp input, which would indicate that you want to estimate the pooled abundance of those species together.
Rare unidentified taxa
A similar problem occur when you have species codes for unidentified taxa that have been identified down to a family- or genus-level. For example, “Unidenfitied Mesoplodon” is a species code (the code is "050") for any beaked whale that is definitely in the genus Mesoplodon. There are plenty of these sightings, which means g(0) and its CV can be estimated just fine without referring to other species codes.
Other unidentified taxa, however, are less common. For example, in Hawaiian studies, density/abundance is estimated for “Unidentified rorquals”. In the field there is a species code for this group, "070", but it is rarely used – there are enough sightings to model the detection function, but not nearly enough sightings to estimate g(0) or its CV. In this case, we need to combine g(0) from more common species codes in order to estimate the unidentified rorqual’s g(0).
To do this, we fit a detection function using species code "070" …
fit_filters <-
list(spp = c('070'),
pool = 'Unidentified rorqual',
cohort = 'all',
truncation_distance = 5.5)… then, in our estimates list, we specify some alternate g(0) species designations.
Geostratum combinations
In your estimates sub-lists, the regions and regions_remove slots give you control of the geographic scope of (1) the weighted g(0) and CV used in density estimation, (2) the effort and sightings used to estimate density, (3) and the area used to calculate abundance.
A note on cohort geostrata
Recall that, when processing your survey data to create a cruz object, you provide a list of geostrata as an argument in your process_surveys() call. You also have the option to specify a subset of those geostrata for each species cohort (see load_cohort_settings()), which is an option that you should almost always use. Selecting a subset of geostrata is important because that subset is used to “segmentize” your survey data – i.e., break effort into discrete sections that can be bootstrap-sampling during the lta() variance estimation routine – and the segmentizing procedure always breaks segments when a survey passes from one geostratum to another.
This matters because the lta() bootstrapping routine will re-sample survey segments in a way that preserves the proportion of segments occurring in each geostratum, to ensure that all geostrata are represented in the same proportion as the original estimate. When segments are unncessarily broken into small segments by irrelevant geostrata that have been included in the analysis, the bootstrap estimate of the CV is likely to be artificially enlarged.
For example: in the Central North Pacific, there are about 11 geostrata commonly used. These include the Hawaiian EEZ geostratum, the Main Hawaiian Islands geostratum, and the larger CNP geostratum that represents the maximum range of the study area. These three geostrata are typically all you need for most density estimates for most species. However, a few species – e.g., bottlenose dolphin, pantropical spotted dolphin, and false killer whale – have special geostrata that represent insular stock boundaries and/or pelagic stock boundaries. If those insular geostrata are used in density estimates for which they do not apply, they will confound the bootstrap estimate of density/abundance CV. Punchline: be sure to specify only the relevant geostrata in each cohort’s settings.
Combining disparate geostrata
For example, in Hawaii bottlenose dolphins belong to a pelagic stock as well as several insular stocks. If you wished to estimate the abundance of all insular stocks together, you simply provide their respective geostratum names in the regions slot of your estimates sub-list:
Removing insular geostrata
Conversely, you may wish to estimate density/abundance for pelagic bottlenose dolphins only, ignoring the insular stocks. You can subtract geostrata using the regions_remove slot:
Combine partially overlapping geostrata
Say you want to estimate the density/abundance for a set of geostrata that partially overlap. An example of this is that the Northwestern Hawaiian Islands geostratum overlaps slightly with the Main Hawaiian Islands geostratum. This is not an issue; when study area is calculated within lta() (actually, that function calls another function, strata_area(), to do this. That function is demonstrated below), overlap among strata is accounted for.
Regionally stratified analysis
Field surveys are sometimes stratified such that trackline design and/or density can differ substantially across regions. Also, analysts may sometimes wish to estimate density/abundance for individual regions separately, regardless of design stratification.
In lta(), you can accommodate a stratified analysis by providing an estimates sub-list for each geostratum. For example, in 2002 the Hawaiian EEZ was surveyed with different effort intensity in the Main Hawaiian Islands region compared to pelagic waters. For that reason, density/abundance estimates ought to be stratified by region:
estimates <- list(
list(spp = '013',
title = 'Striped dolphin',
years = 2002,
regions = 'MHI'),
list(spp = '013',
title = 'Striped dolphin',
years = 2002,
regions = 'HI_EEZ',
regions_remove = 'MHI'))Here we have one 2002 estimate for the Main Hawaiian Islands, and a second for the pelagic Hawiian EEZ, achieved by subtracting the "MHI" stratum from the "HI_EEZ" stratum.
Once lta() processing is complete, you can summarize and plot the results for each study area separately. The next step is to combine the stratified estimates to generate a grand estimate for the entire EEZ. This is achieved using the LTabundR functions lta_enlist() and lta_destratify(). We discuss this further in the next chapter.
Subgroup-based analyses
After 2010, NOAA Fisheries Pacific Islands Fisheries Science Center began a sub-group protocol referred to as the “PC Protocol” after the scientific name for false killer whales, Pseudorca crassidens, the species for which the protocol was designed.
False killer whales are rare and occur in dispersed subgroups, which complicates conventional distance sampling approaches to line-transect analysis.
To handle this, a separate, subgroup-based analytical approach was developed (Bradford et al. 2014). This approach could theoretically be used for other species that occur in subgroups. We cover this in a subsequent chapter.
Custom covariates
You can only fit detection functions with covariates that exist in your cruz object, specifically within the cruz$cohorts$<cohort>$sightings dataset. However, you are free to add columns to that dataset after processing in order to include custom covariates within your line-transect analysis. Here is an example of how to do so:
Say you wanted to add swell height anomaly as a detection function covariate. First, add this column to your sightings data:
# Get average swell across all cruz effort
(avg_swell <- cruz$cohorts$all$das$SwellHght %>% mean(na.rm=TRUE))
[1] 5.237323
# Get sighting swell height values
swells <- cruz$cohorts$all$sightings$SwellHght
# Add anomaly column to sightings dataset
cruz$cohorts$all$sightings$swell_anomaly <- swells - avg_swellReview histogram of new covariate:
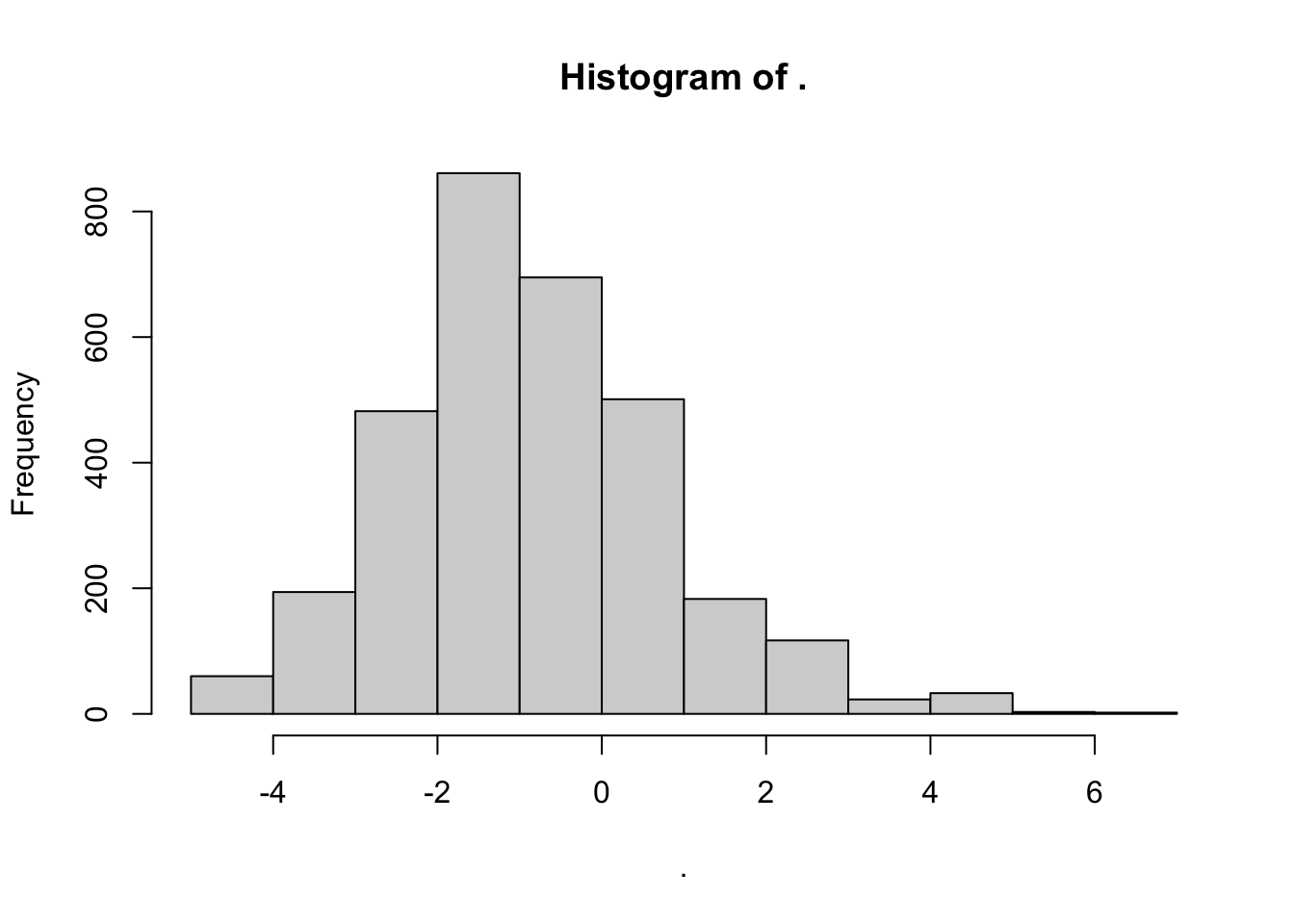
Now update the df_settings with your new covariate:
df_settings = list(covariates = c('bft','lnsstot','species', 'swell_anomaly'),
covariates_factor = c(FALSE, FALSE, TRUE, FALSE),
covariates_levels = 2,
covariates_n_per_level = 10,
simplify_cue = TRUE,
simplify_bino = TRUE,
detection_function_base = 'hn',
base_model = '~1',
delta_aic = 2)Now try using it as a covariate in a run of the lta() function for one of the simple estimates we did above:
Specify fit_filters for this example:
fit_filters = list(spp = c('013', '026', '031'),
pool = 'Multi-species pool 1',
cohort = 'all',
truncation_distance = 5,
other_species = 'remove')Specify our estimate of interest for this example:
estimates <- list(list(spp = '013',
title = 'Striped dolphin',
years = 2017,
regions = 'WHICEAS',
g0=1, g0_cv=0))Run the line-transect analysis:
Check out the detection functions that were evaluated:
Behind the scenes
Step-by-step operations
The following list is a summary of each step of the lta() function, in order of operations.
Function inputs are checked for valid formatting, and any optional inputs that are not user-provided are given default values.
For each sublist in your
estimatesinput, the following actions are taken:Sublist inputs are checked for valid formatting, and any optional inputs that are not user-provided are given default values.
A polygon is created based on the sublist’s slots for
regions(strata to include in abundance estimation) andregion_remove(strata to exclude). This process is detailed in the Area Estimation section below.The spatial area, in square km, is calculated for that polygon.
Weighted
g(0)values are estimated based on the survey effort related to this sublist:Determine the species code(s) to be used to filter the
Rg0dataset. Usually this is the species code(s) in thesppslot, but if the sublist has analt_g0slot, the code(s) in that slot is used to filter theRg(0)dataset. If multiple codes are provided, and the sublist has a slot namedcombine_g0with the valueTRUE, then weighted g(0) values will be estimated for each species then those values will be averaged together a few steps down. (If multiple species codes are provided butcombine_g0is not provided or isFALSE, then only the first species code will be used.) If the species code(s) are not found in theRg0dataset, weighted g(0) will be coerced to 1.0 with CV of 0.Survey effort is filtered down according to the relevant slots in the sublist –
years,regions(the strata to include), and, optionally,regions_remove(the strata to exclude) — as well as thelta()inputsabund_eff_types(whichEffortTypevalues are usable for abundance estimation) andabund_bft_range(which Beaufort sea states are usable).That survey effort is used to estimate weighted g(0) and its CV for each species code using the
LTabundRfunctiong0_weighted(). That function does the following:Determines the proportion of survey effort occurring in each Beaufort state (this is done using the
LTabundRfunctionsummarize_bft()).Uses those sea state proportions as weights to calculate the weighted mean g(0) based on the values in
Rg(0). For example, if theRg(0)values for species code"046"(sperm whale) in Beaufort states 0 to 6 are 1.00, 0.87, 0.75, 0.65, 0.57, 0.49, and 0.42, respectively, and the proportion of effort in those respective sea states are 0.01, 0.03, 0.07, 0.19, 0.35, 0.24, and 0.11, then the weighted g(0) is0.679. This weighted g(0) is the value provided in the final results table for the function.To estimate the CV of this weighted g(0), a MCMC routine is used that first approximates the distribution of g(0) … (details needed here) … This is essentially a direct adaptation of the code developed by Jeff Moore and Amanda Bradford, and described in Bradford et al. (2021).
If multiple species codes were provided and therefore multiple estimates of weighted g(0) were produced, those estimates are averaged using the
LTabundRfunctiong0_combine(). That function uses the same equations as the Excel spreadsheet used in the Bradford et al. (2022) WHICEAS study.The sublist is updated with these resulting values: the study area polygon, the estimated of weighted g(0), its CV, and the proportional effort in each Beaufort state.
A reference list is built containing details for the g(0) distributions for each sublist in
estimates. This is done in order to facilitate easy recall during the bootstrapping phase later on in the function. Each weighted g(0) and its CV are passed to theLTabundRfunctiong0_optimize(), which returns the parameters needed to generate a distribution from which to draw bootstrap values of g(0). That function is a near-exact replica of the code developed by Jay Barlow to produce bootstrapped estimates in Barlow (2006). It involves an optimization routine which can take several seconds to complete, so this step is conducted once here rather than repeatedly during bootstrap iterations.The
cruzobject is filtered to survey data for the specifiedcohort, to segments for which the columnuseisTRUE, and to sightings for which the columnincludedisTRUE. The sightings are filtered further to include only the species specified in the inputfit_filters$spp. The resulting datasets will be used for modeling the detection function, and a subset of the datasets will be used for estimating abundance.Handling “Other” species designations: if the input
fit_filtershas a slot forother_species, certain species codes in mixed-species sightings may be modified if they do not constitute the plurality of the group size. See details in Fit filters above.If any of the covariates requested within the input
df_settings$covariateshave missing values (i.e.,NA), those sightings will be removed from the dataset used for fitting detection functions and estimating abundance. Similarly, any sightings with invalid group size estimates (the columnss_valid == FALSE) are removed.The sample sizes used in fitting the detection function are stored.
If the input
df_settings$simplify_cueexists and isTRUE, cue codes (columnCuein the sightings dataset) are simplified to aid in overcoming factor level sample size limitations.If the input
df_settings$simplify_binoexists and isTRUE, sighting method codes (columnMethodin the sightings dataset) are simplified to aid in overcoming factor level sample size limitations.If any of the covariates to be used in modeling the detection function should be treated as a factor (this is specified in the input
df$covariates_factor), then the covariates columns are updated as such. All covariates specified as a factor are first tested for eligibility. Only factors with at least two levels (or whatever you specified withdf_settings$covariates_levels) and 10 observations in each level (or whatever you specified withdf_settings$covariates_n_per_level) are eligible for inclusion in the final set of covariates.The final results object is staged; this is a list with slots for data regarding the species pool, the inputs used, the detection function model, and the resulting estimates.
A large loop is then initiated, with the first iteration being the formal estimate. Subsequent iterations are part of the bootstrapping process for estimating CV and confidence intervals.
The detection function is modelled based on the sightings, covariates and truncation distance provided. This is done by calling the
LTabundRfunctiondf_fit(), which depends upon the detection function modeling functionmrds()from the packageDistance. See further details in the section below on “Fitting a detection function”. Detailed results of the best-fit model are stored, its detection curve is generated using theLTabundRfunctiondf_curve(), and the Effective Strip Half-Width estimates for each sighting is added to the sightings data.Segments and sightings are filtered to only data appropriate for estimating density/abundance. This means
OnEffortisTRUE,EffortTypeis one of the variables in thelta()inputabund_efftypes(the defaults is just"S"),Bftcan be rounded to one of the values provided in the inputabund_bft_range(the default is0:6), and sightings occur within the truncation distance.Loop through each sublist in the
lta()inputestimates:Segments and sightings are filtered to the species, years, cruises, and regions specified.
Abundance is estimated using the
LTabundR()functionabundance(), based upon the filtered data and the g(0) value for this sublist. The resulting Effective Strip Half-Width (ESW) is based on the mean ESW of the sightings used to estimate abundance. The resulting g(0) is based on the mean weighted g(0) value for each sighting, since in some use cases a different g(0) value is supplied for small vs. large schools.Results are stored.
If a filepath was supplied for the
lta()inputresults_file, anRDataobject with all of the results up to this point is saved to file.
The loop is repeated for bootstrap iterations if the
lta()inputbootstrapsis notNULLand is a number greater than0. The differences in these bootstrap iterations from the original estimate routine are as follows:Before the detection function is modeled, bootstrapped versions of the segments and sightings are generated using the
LTabundRfunctionprep_bootstrap_datasets(). This function (1) determines the number of segments occurring within each stratum; (2) resamples the segment IDs within each stratum (with replacement), to yield the same number of segments (though some segments may be replicated) and preserve the relative distribution of effort across strata; then (3) gathers the sightings associated with each of those bootstrapped segments. If a segment is counted twice, two copies of its respective sightings are used. These new versions of the segments and sightings are used to model the detection function, and are then filtered to estimate density/abundance.Before abundance is estimated, a new g(0) value is drawn randomly from a distribution that is based on the parameters stored in the reference table described in step 3 above. The code for doing this is copied directly from the routine written by Jay Barlow’s for his 2006 report.
After abundance is estimated, details of the bootstrap iteration are saved and the
results_fileis updated.
At the end of all bootstrap iterations, a summary of the bootstrap iteration process is generated and the
results_fileis updated. The CV of g(0) in this summary table is based on the bootstrapped values of g(0). The confidence intervals for density/abundance in this summary table are generated using theLTabundRfunctionlta_ci().
Other details
Area estimation {-}
Unless you manually specify the study area in your estimates list, lta() will calculate your study area for you based on the geostrata you provide. It does so by calling the LTabundR function strata_area(), which you can use on your own to explore geostratum combination options. This function was designed using the sf package to handle complex polygon combinations, and it uses Natural Earth datasets to remove land within your study area (this is a feature you can turn off, if you want).
Here are some examples of how strata_area() handles complex scenarios.
Say you want to estimate abundance in the ‘WHCEAS’ study area, but you want to make sure the study area estimate is accurately removing land:
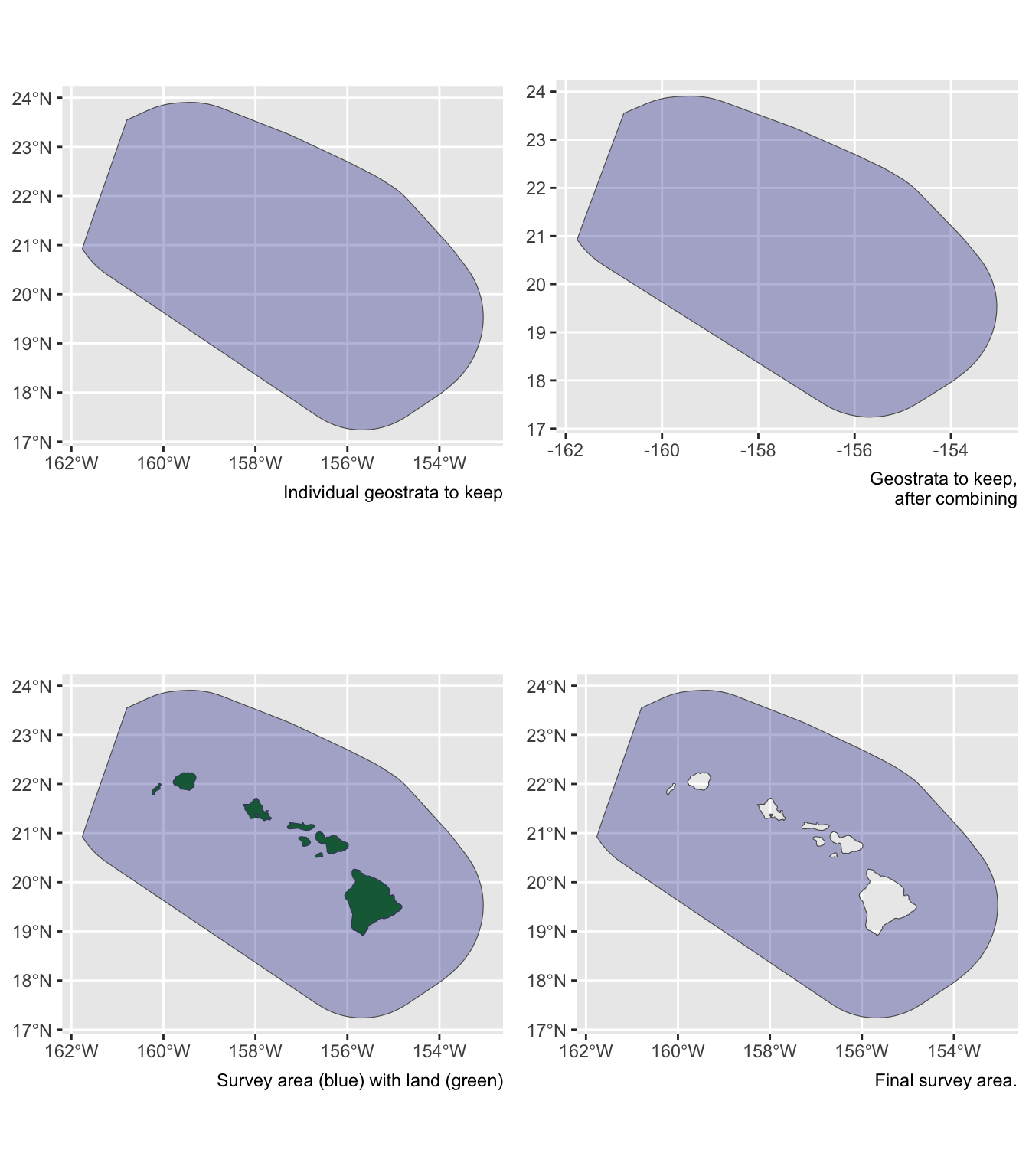
Say you want to estimate abundance in the pelagic Hawaiian EEZ, ignoring effort and sightings within the Main Hawaiian Islands stratum and accurately removing the area of the small Northwestern Hawaaian Islands:
demo <- strata_area(strata_all = cruz$settings$strata,
strata_keep = c('HI_EEZ'),
strata_remove = c('MHI'),
verbose = FALSE)
strata_all = cruz$settings$strata
strata_keep = c('HI_EEZ')
strata_remove = c('MHI')
verbose = FALSESay you want to estimate abundance of pelagic bottlenose dolphins within the WHICEAS study area, ignoring the insular stocks:
demo <- strata_area(strata_all = cruz$settings$strata,
strata_keep = c('WHICEAS'),
strata_remove = c('Bottlenose_KaNi','Bottlenose_OUFI','Bottlenose_BI'),
verbose = FALSE)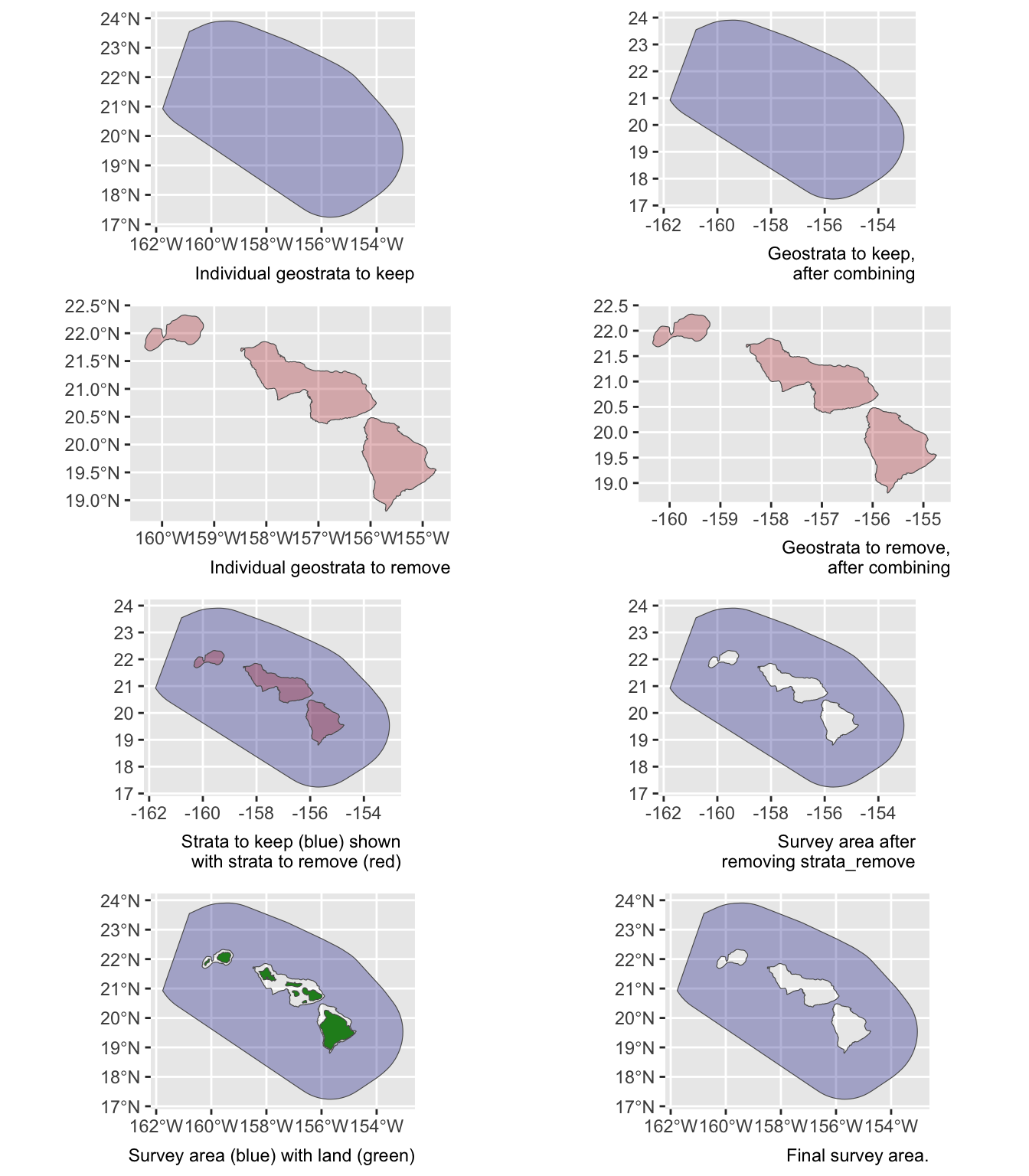
Say you want to estimate abundance for only the insular bottlenose stocks:
demo <- strata_area(strata_all = cruz$settings$strata,
strata_keep = c('Bottlenose_KaNi','Bottlenose_OUFI','Bottlenose_BI'),
verbose = FALSE)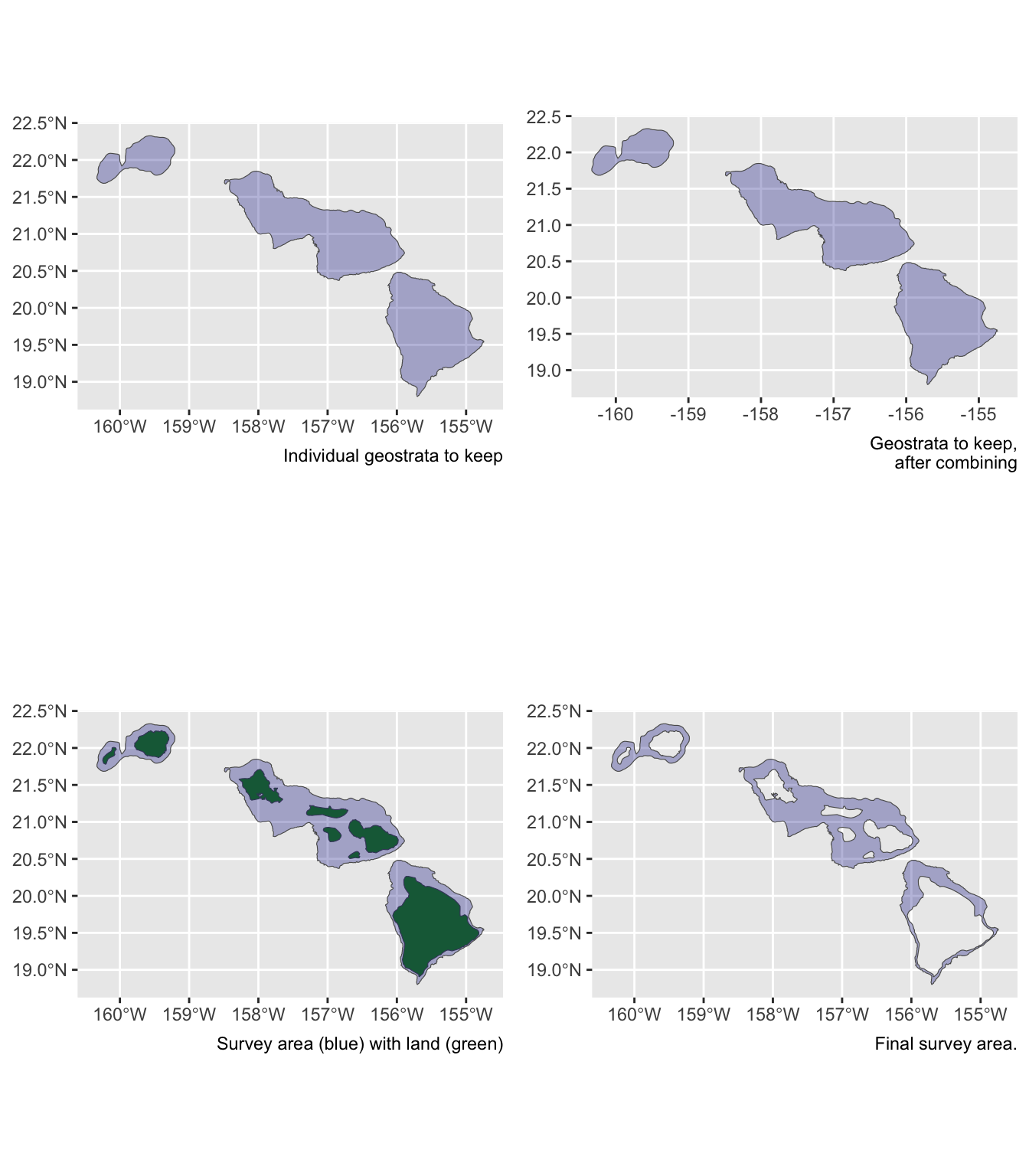
Say you want to estimate abundance for false killer whales within the Northwestern Hawaiian Islands and Main Hawaiian Islands study areas combined, but those geostrata partially overlap:
demo <- strata_area(strata_all = cruz$settings$strata,
strata_keep = c('MHI','nwhi_fkw'),
verbose = FALSE)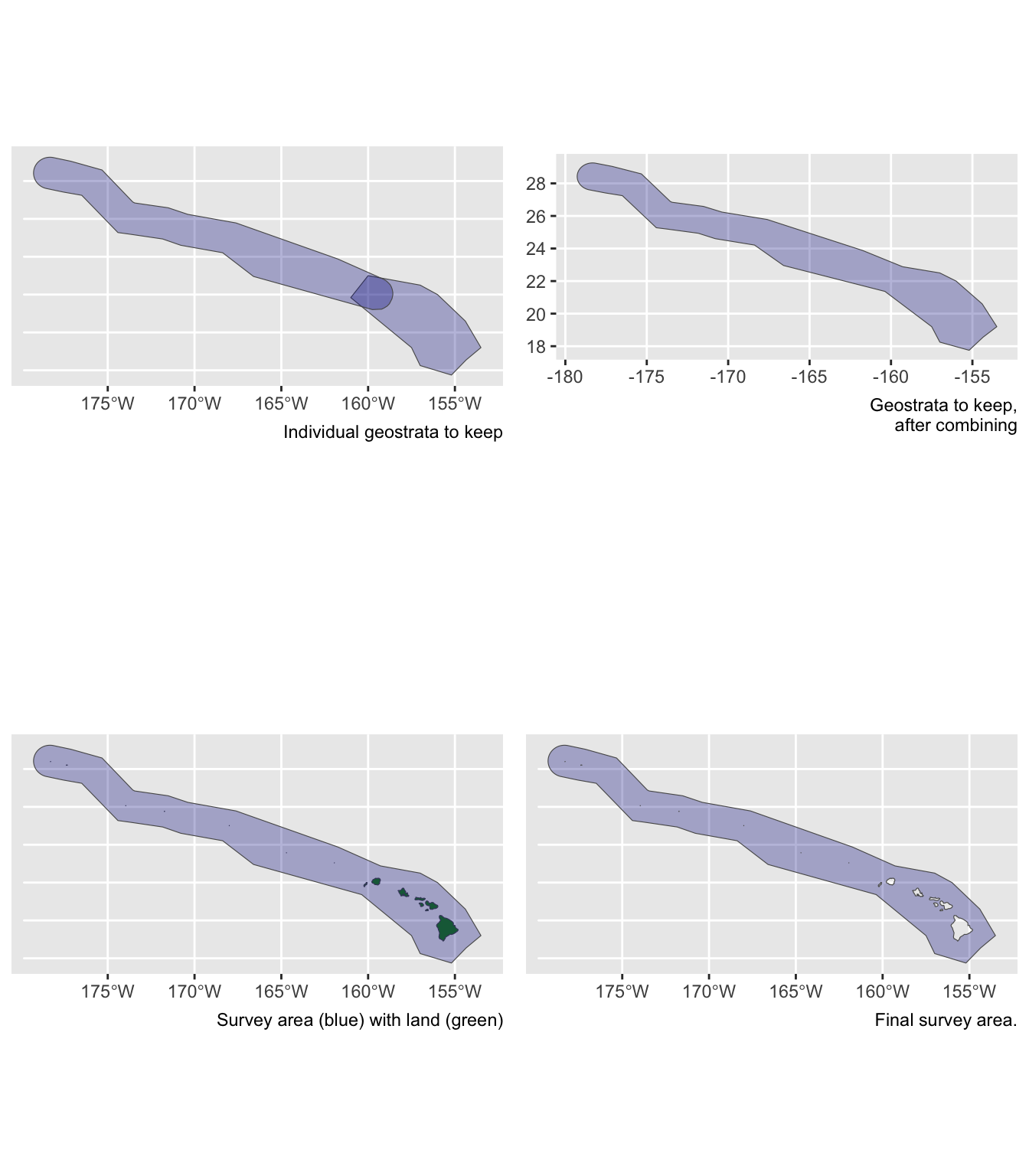
Say you want to estimate abundance for the Hawaiian EEZ outside of those partially overlapping geostrata:
demo <- strata_area(strata_all = cruz$settings$strata,
strata_keep = 'HI_EEZ',
strata_remove = c('MHI','nwhi_fkw'),
verbose = FALSE)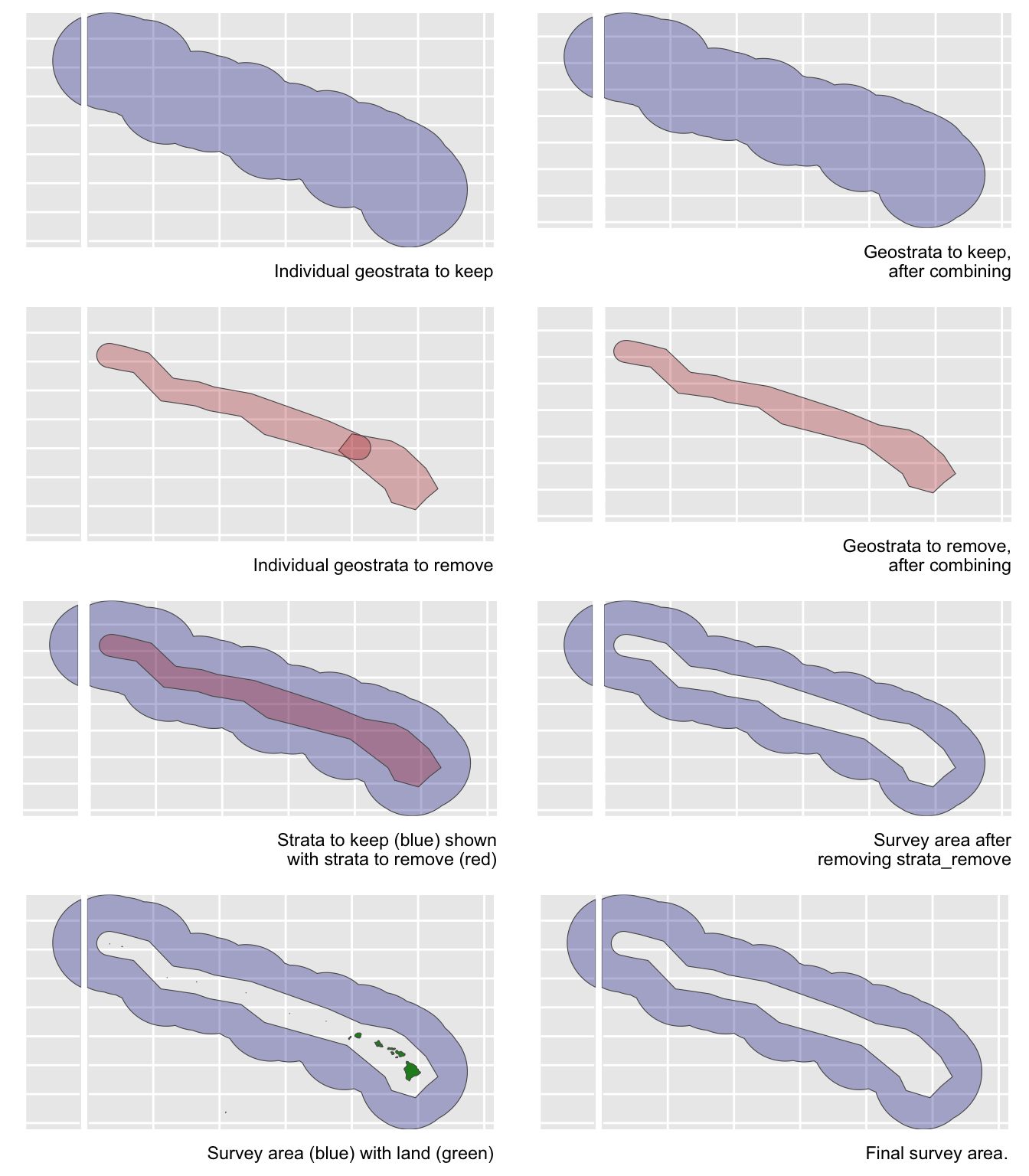
g(0) estimation
If you want lta() to calculate a weighted g(0) estimate (and associated CV) that is specific to the conditions associated with your estimates sub-list parameters, all you need to do is provide the Rg0 input. When you do this, the lta() function will find the Rg0 values associated with the species code(s) in your estimates sub-list, then calculate weighted g(0) and its CV using the LTabundR function, g0_weighted(), which we discussed and demonstrated on the previous page.
If lta() can’t find your species code in the Rg0 table you provide, it will give up and assume that g(0) is 1.0 and that g0_cv is 0.0.
If your estimates sub-list has a alt_g0_spp slot, lta() will use that species code instead to filter the Rg0 table.
If your estimates sub-list has a combine_g0 slot that is TRUE, lta() will filter the Rg0 table using all species codes you provide. If that filtration results in multiple Rg0 species being found, weighted g(0) will be calculated for each of those species separately, then those g(0) estimates will be combined using a geometric mean (using the LTabundR function g0_combine()). If combine_g0 is FALSE, only the first species code provided in your estimates sub-list will be used to filter Rg0.
If you want to supply a weighted g(0) estimate and its CV yourself, you can add the g0 and g0_cv slots to your estimates sublist, as explained above.
If you want to coerce g(0) to be assumed to be 1.0 (with CV = 0.0), you can either (1) not supply the Rg0 input, or (2) manually specify the g0 and g0_cv slots in your estimates sub-list accordingly.
Fitting a detection function {-}
The detection function is estimated using functions in the package mrds, primarily the main function mrds::ddf(), which uses a Horvitz-Thompson-like estimator to predict the probability of detection for each sighting. If multiple base key functions (e.g., half-normal or hazard-rate) are provided, and/or if covariates are specified, model fitting is done in a forward stepwise procedure:
- In the first round, the base model (no covariates, i.e.,
"~1") is fit first.
- In the second round, each covariate is added one at a time; at the end of the round, the covariate, if any, that produces the lowest AIC below the AIC from the previous round is added to the formula.
- This process is repeated in subsequent rounds, adding a new covariate term in each round, until the AIC no longer improves.
- If a second base key is provided, the process is repeated for that second key.
All models within delta_aic of the model with the lowest AIC qualify as best-fitting models. The best-fitting model(s) is(are) then used to estimate the Effective Strip half-Width (ESW) based on the covariates associated with each sighting.
If multiple best-fitting models occur, we will find the average ESW for each sighting across all models, using a weighted mean approach in which we weight according to model AIC. To turn off this model averaging step, set delta_aic to 0 to avoid passing multiple models to the abundance estimation stage.
Note that if lnsstot is included as a covariate, the function will (1) check to see if the sightings dataframe has a column named ss_valid (all cruz objects do), then, if so, (2) filter sightings only to rows where ss_valid is TRUE, meaning the group size estimate for that sighting is a valid estimate. This means that the sample size used for fitting a detection function could be reduced if there are sightings with ss_valid = FALSE and lnsstot is used as a covariate in the fitting routine.
This stage of the lta() command is executed within a backend function, LTabundR::fit_df(), which has its own documentation for your reference.
Estimating density & abundance
Estimates are produced for various combinations of species, regions, and years, according to the arguments specified in your estimates list(s). Before these estimates are produced, we filter the data used to fit the detection function to strictly systematic (design-based) effort (i.e., EffType = "S"), in which standard protocols are in use (i.e., OnEffort = TRUE) and the Beaufort sea state is less than 7 (though these controls can be modified using the lta() inputs abund_eff_types and abund_bft_range (see above).
Note that if sightings has a column named ss_valid (all standard cruz objects do) and if any of the rows in that column are FALSE, those sightings will be removed, since density/abundance estimation depends absolutely upon reliable group size estimates. This will artificially reduce your density/abundance estimate, which is a serious problem. To review your data for any invalid group size estimates for the species-region-year of interest for your density/abundance estimate, see the LTabundR function lta_checks() (presented higher up in this chapter).
This stage of the lta() command is executed within a back-end function, LTabundR::abundance(), which has its own documentation for your reference.
Bootstrap variance estimation
If the bootstraps input value is greater than 1, bootstrap variance estimation will be attempted. In each bootstrap iteration, survey segments are re-sampled with replacement before fitting the detection function and estimating density/abundance. Re-sampling is done in a routine that preserves the proportion of segments from each geostratum.
Note that the entire process is repeated in each bootstrap: step-wise fitting of the detection function, averaging of the best-fitting models, and density/abundance estimation for all species/region/year combinations specified in your estimates input. At the end of the bootstrap process, results are summarized for each species/region/year combination. 95% confidence intervals are calculated using the BCA method (package coxed, function bca()).
g(0) values during bootstrapping
When conducting the non-parametric bootstrap routine to estimate the CV of density and abundance, uncertainty is incorporated into the g(0) value in each iteration using a parametric bootstrapping subroutine: First, a logit-transformed distribution is modeled based upon the mean and CV of g(0) provided by the user in the estimates input (see documentation for LTabundR::g0_optimize() for details on this step). This modeled distribution is used to randomly draw a g(0) value for each iteration of the density/abundance bootstrap routine. In this way, the uncertainty in g(0) is propagated into uncertainty in density/abundance.
Returned estimates for weighted g(0)
Note that the results object returned by lta() (we will refer to this object as lta_result here) contains various g(0) estimates in various places. Here is a key:
In lta_result$estimate, you will find the columns g0_small (the weighted g(0) estimate for small group sizes) and g0_large (the weighted g(0) estimate for large group sizes). These values may differ if you manually provided different weighted g(0) estimates for small and large schools. In most cases, however, the two values will be the same. You will also find the column g0_est, which is the average g(0) of the detections used for the point estimate. This can differ from g0_small and g0_large since some schools may be large and some may be small. You will also find g0_cv_small and g0_cv_large which are the CV’s of g0_small and g0_large, respectively, that are estimated using a Monte Carlo Markov Chain routine described in the Step-by-Step outline provided above. If small vs large estimates of g(0) do not differ, the CVs will be the same. These four values (g0_small, g0_large, g0_cv_small, and g0_cv_large) are the weighted g(0) estimates reported by the LTabundR functions provided for summarizing your results (e.g., lta_diagnostics() and lta_report()).
In lta_result$bootstrap$summary, you will find the columns g0_mean and g0_cv, which report the mean and CV, respectively, of the parametric bootstrap values of g(0) used in each bootstrap iteration. These should be similar to the g(0) values you find in lta_result$estimate but will maybe not exactly equal.
In lta_result$bootstrap$details, you will find a column g0_est which provides the bootstrapped g(0) value used in each iteration of the bootstrap routine.